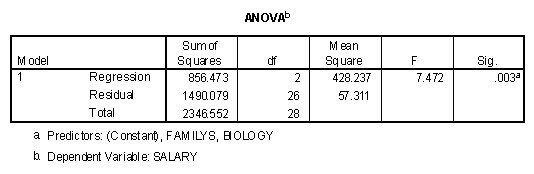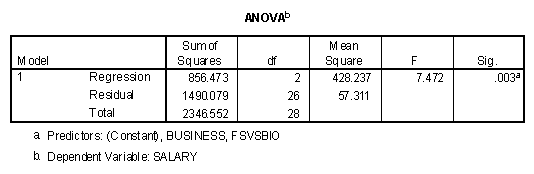When a researcher wishes to include a categorical variable with more than two level in a multiple regression prediction model, additional steps are needed to insure that the results are interpretable. These steps include recoding the categorical variable into a number of separate, dichotomous variables. This recoding is called "dummy coding." In order for the rest of the chapter to make sense, some specific topics related to multiple regression will be reviewed at this time.
Multiple regression is a linear transformation of the X variables such that the sum of squared deviations of the observed and predicted Y is minimized. The prediction of Y is accomplished by the following equation:
Y'i = b0 + b1X1i + b2X2i + ... + bkXki
The "b" values are called regression weights and are computed in a way that minimizes the sum of squared deviations.
Categorical variables with two levels may be directly entered as predictor or predicted variables in a multiple regression model. Their use in multiple regression is a straightforward extension of their use in simple linear regression. When entered as predictor variables, interpretation of regression weights depends upon how the variable is coded. If the dichotomous variable is coded as 0 and 1, the regression weight is added or subtracted to the predicted value of Y depending upon whether it is positive or negative. If the dichotomous variable is coded as -1 and 1, then if the regression weight is positive, it is subtracted from the group coded as -1 and added to the group coded as 1. If the regression weight is negative, then addition and subtraction is reversed. Dichotomous variables can be included in hypothesis tests for R2 change like any other variable.
A block of variables can simultaneously be entered into an hierarchical regression analysis and tested as to whether as a whole they significantly increase R2, given the variables already entered into the regression equation. The degrees of freedom for the R2 change test corresponds to the number of variables entered in the block of variables.
Adding variables to a linear regression model will always increase the unadjusted R2 value. If the additional predictor variables are correlated with the predictor variables already in the model, then the combined results are difficult to predict. In some cases, the combined result will provide only a slightly better prediction, while in other cases, a much better prediction than expected will be the outcome of combining two correlated variables.
If the additional predictor variables are uncorrelated (r = 0.0) with the predictor variables already in the model, then the result of adding additional variables to the regression model is easy to predict. Namely the R2 change will be equal to the correlation coefficient squared between the added variable and predicted variable. In this case it makes no difference what order the predictor variables are entered into the prediction model. For example, if X1 and X2 were uncorrelated (r12 = 0) and r1y2 = .3 and r2y2 = .4, then R2 for X1 and X2 would equal .3 + .4 = .7. The value for R2 change for X2 given X1 was in the model would be .4. The value for R2 change for X2 given no variable was in the model would be .4. It would make no difference at what stage X2 was entered into the model, the value for R2 change would always be .4. Similarly, the R2 change value for X1 would always be .3. Because of this relationship, uncorrelated predictor variables will be preferred, when possible.
The following is simulated data.
| Faculty | Salary | Gender | Rank | Dept | Years | Merit |
|---|---|---|---|---|---|---|
| 1 | 38 | 0 | 3 | 1 | 0 | 1.47 |
| 2 | 58 | 1 | 2 | 2 | 8 | 4.38 |
| 3 | 80 | 1 | 3 | 9 | 3.65 | |
| 4 | 30 | 1 | 1 | 1 | 0 | 1.64 |
| 5 | 50 | 1 | 1 | 3 | 0 | 2.54 |
| 6 | 49 | 1 | 1 | 3 | 1 | 2.06 |
| 7 | 45 | 0 | 3 | 1 | 4 | 4.76 |
| 8 | 42 | 1 | 1 | 2 | 0 | 3.05 |
| 9 | 59 | 0 | 3 | 3 | 3 | 2.73 |
| 10 | 47 | 1 | 2 | 1 | 0 | 3.14 |
| 11 | 34 | 0 | 1 | 1 | 3 | 4.42 |
| 12 | 53 | 0 | 2 | 3 | 0 | 2.36 |
| 13 | 35 | 1 | 1 | 1 | 1 | 4.29 |
| 14 | 42 | 0 | 1 | 2 | 2 | 3.81 |
| 15 | 42 | 0 | 1 | 2 | 2 | 3.84 |
| 16 | 51 | 0 | 3 | 2 | 7 | 3.15 |
| 17 | 51 | 1 | 2 | 1 | 8 | 5.07 |
| 18 | 40 | 0 | 1 | 2 | 3 | 2.73 |
| 19 | 48 | 1 | 2 | 1 | 1 | 3.56 |
| 20 | 34 | 1 | 1 | 1 | 7 | 3.54 |
| 21 | 46 | 1 | 2 | 1 | 2 | 2.71 |
| 22 | 45 | 0 | 1 | 2 | 6 | 5.18 |
| 23 | 50 | 1 | 1 | 3 | 2 | 2.66 |
| 24 | 61 | 0 | 3 | 3 | 3 | 3.7 |
| 25 | 62 | 1 | 3 | 1 | 2 | 3.75 |
| 26 | 51 | 0 | 1 | 3 | 8 | 3.96 |
| 27 | 59 | 0 | 3 | 3 | 0 | 2.88 |
| 28 | 65 | 1 | 2 | 3 | 5 | 3.37 |
| 29 | 49 | 0 | 1 | 3 | 0 | 2.84 |
| 30 | 37 | 1 | 1 | 1 | 9 | 5.12 |
It is fairly clear that Gender could be directly entered into a regression model predicting Salary, because it is dichotomous. The problem is how to deal with the two categorical predictor variables with more than two levels (Rank and Dept).
because categorical predictor variables cannot be entered directly into a regression model and be meaningfully interpreted, some other method of dealing with information of this type must be developed. In general, a categorical variable with k levels will be transformed into k-1 variables each with two levels. For example, if a categorical variable had six levels, then five dichotomous variables could be constructed that would contain the same information as the single categorical variable. Dichotomous variables have the advantage that they can be directly entered into the regression model. The process of creating dichotomous variables from categorical variables is called dummy coding.
Depending upon how the dichotomous variables are constructed, additional information can be gleaned from the analysis. In addition, careful construction will result in uncorrelated dichotomous variables. As discussed earlier, these variables have the advantage of simplicity of interpretation and are preferred to correlated predictor variables.
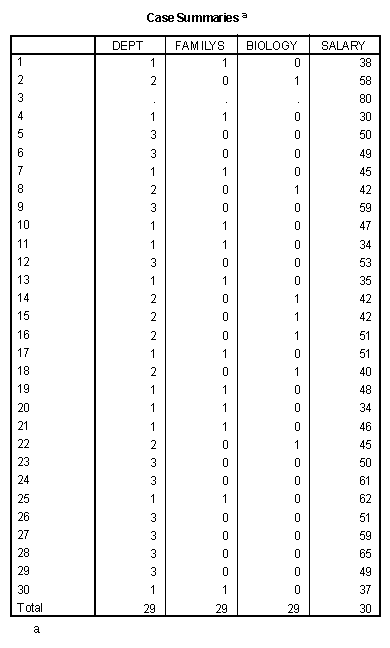
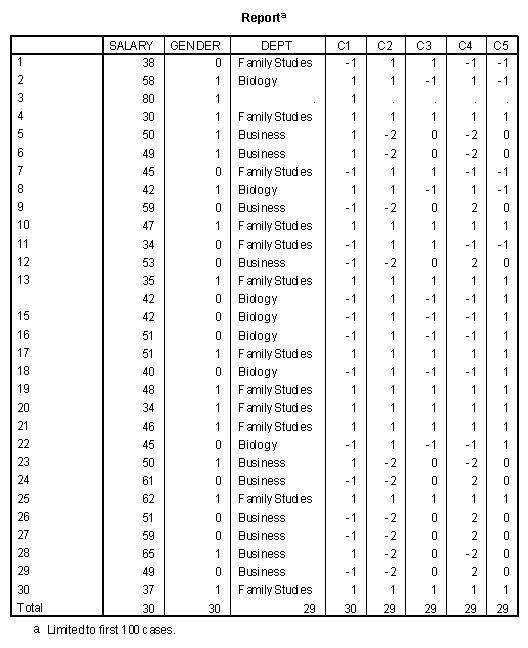
The simplest case of dummy coding is when the categorical variable has three levels and is converted to two dichotomous variables. For example, Dept in the example data has three levels, 1=Family Studies, 2=Biology, and 3=Business. This variable could be dummy coded into two variables, one called FamilyS and one called Biology. If Dept = 1, then FamilyS would be coded with a 1 and Biology with a 0. If Dept=2, then FamilyS would be coded with a 0 and Biology would be coded with a 1. If Dept=3, then both FamilyS and Biology would be coded with a 0. The dummy coding is represented below.
| Dept | FamilyS | Biology | |
|---|---|---|---|
| Family Studies | 1 | 1 | 0 |
| Biology | 2 | 0 | 1 |
| Business | 3 | 0 | 0 |
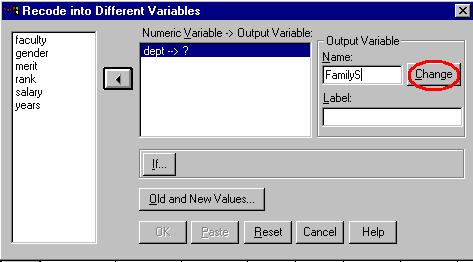
The dummy coding can be done using SPSS and the Transform/RecodeInto different Variable... options. The Dept variable is the "Numeric Variable" that is going to be transformed. In this case the FamilyS variable is going to be created. The window on the screen should appear as follows:
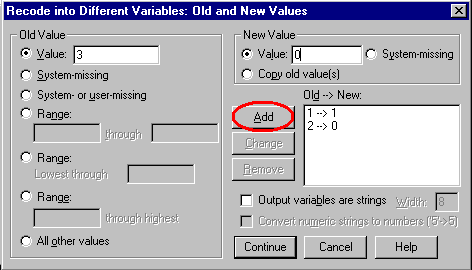
Clicking on the Change button and then on the Old and New Values... button will result in the following window:
The Old Value is the level of the categorical variable to be changed, the New Value is the value on the transformed variable. In the example window above, a value of 3 on the Dept variable will be coded as a 0 on the FamilyS variable. The Add button must be pressed to add the recoding to the list. When all the recodings have been added, click on the Continue button and then the OK button.
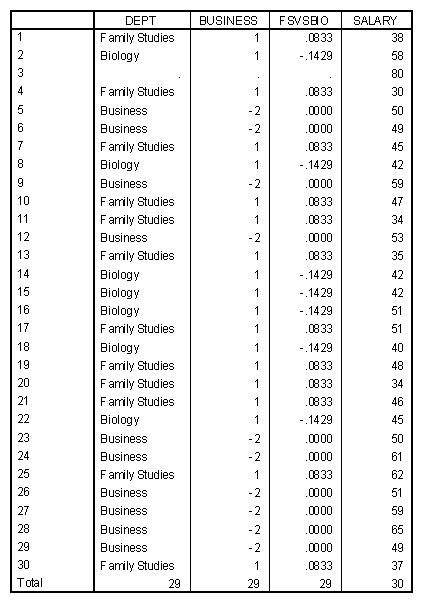
The recoding of the Biology is accomplished in the same manner. A listing of the data is presented below.
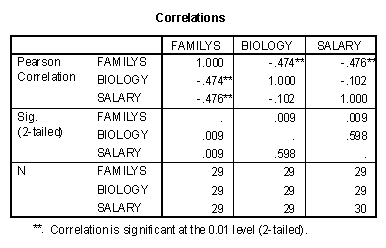
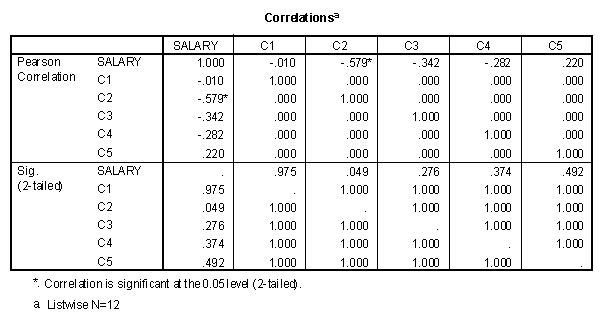
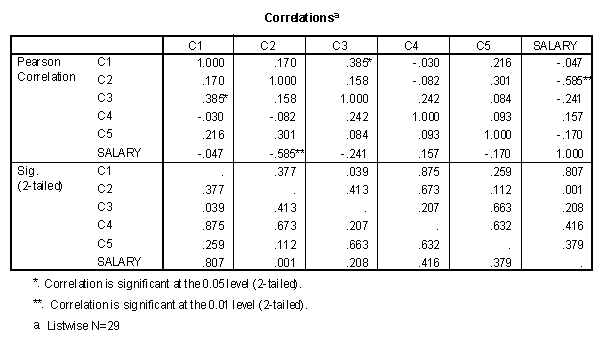
The correlation matrix of the dummy variables and the Salary variable is presented below.
Two things should be observed in the correlation matrix. The first is that the correlation between FamilyS and Biology is not zero, rather it is -.474. Second is that the correlation between the Salary variable and the two dummy variables is different from zero. The correlation between FamilyS and Salary is significantly different from zero.
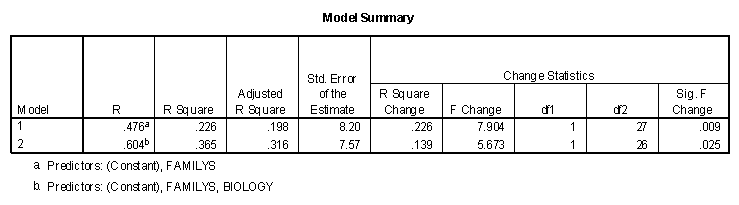
The results of predicting Salary from FamilyS and Biology using a multiple regression procedure are presented below. The first table enters FamilyS in the first block and Biology in the second. The second table reverses the order that the variables are entered into the regression equation. The model summary tables are presented below.
In the first table above both FamilyS and Biology are significant. In the second, only FamilyS is statistically significant. Note that both orderings end up with the same value for multiple R (.604). It makes a difference what order the variables are entered into the regression equation in the hierarchical analysis.
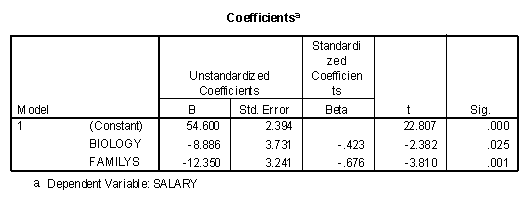
In the next tables, both FamilyS and Biology have been entered in the first block. The model summary table, ANOVA, and Coefficients tables are presented below.
The ANOVA and model summary tables contain basically redundant information in this case. The Coefficients table can be interpreted as Biology making 8.886 thousand dollars less in salary per year relative to the Business department, while the Family Studies department make 12.350 thousand dollars less than the Business department. Note that the "Sig." levels in the "Coefficients" table are the same as the significance levels of the model summary tables presented earlier when each of the dummy coded variables is entered into the regression equation last.
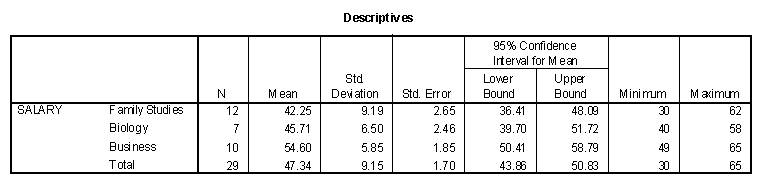
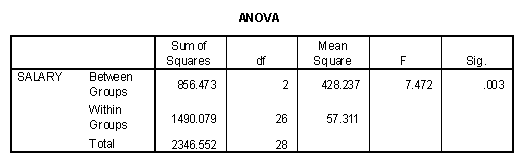
The results of the preceding analysis can be compared to the results of using the ANOVA procedure in SPSS with Salary as the dependent measure and Dept as the independent. The following table presents the table of means and ANOVA table.
Note first that the ANOVA tables produced using the ANOVA command and the Linear Regression command are identical. ANOVA is a special case of linear regression when the variables have been dummy coded. The second notable comparison of the tables involves the regression weights and the actual differences between the means. Note that the regression weight for FamilyS in the regression procedure is -12.350 and the difference between the means of the Family Studies department (42.25) and the Business department (54.60) is -12.350.
Selection of an appropriate set of dummy codes will result in new variables that are uncorrelated or independent of each other. In the case when the categorical variable has three levels this can be accomplished by creating a new variable where one level of the categorical variable is assigned the value of -2 and the other levels are assigned the value of 1. The signs are arbitrary and may be reversed, that is, values of 2 and -1 would work equally well. The second variable created as a dummy code will have the level of the categorical variable coded as -2 given the value of 0 and the other values recoded as 1 and -1. In all cases the sum of the dummy coded variable will be zero. Trust me, this is actually much easier than it sounds.
Interpretation is straightforward. Each of the new dummy coded variables, called a contrast, compares levels coded with a positive number to levels coded with a negative number. Levels coded with a zero are not included in the interpretation.
For example, Dept in the example data has three levels, 1=Family Studies, 2=Biology, and 3=Business. This variable could be dummy coded into two variables, one called Business (comparing the Business Department with the other two departments) and one called FSvsBio (for Family Studies versus Biology.) The Business contrast would create a variable where all members of the Business Department would be given a value of -2 and all members of the other two departments would be given a value of 1. The FSvsBio contrast would assign a value of 0 to members of the Business Department, 1 divided by the number of members of the Family Studies Department to member of the Family Studies Department, and -1 divided by the number of members of the Biology Department to members of the Biology Department. The FSvsBio variable could be coded as 1 and -1 for Family Studies and Biology respectively, but the recoded variable would no longer be uncorrelated with the first dummy coded variable (Business). In most practical applications, it makes little difference whether the variables are correlated or not, so the simpler 1 and -1 coding is generally preferred. The contrasts are summarized in the following table.
| Dept | Business | FSvsBio | |
|---|---|---|---|
| Family Studies | 1 | 1 | 1/N1 = 1/12= .0833 |
| Biology | 2 | 1 | -1/N2 = -1/7 = -.1429 |
| Business | 3 | -2 | 0 |
The data matrix with the dummy coded variables would appear as follows.
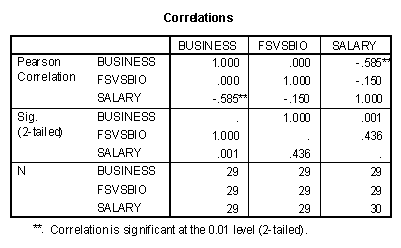
The correlation matrix containing the two contrasts and the Salary variable is presented below.
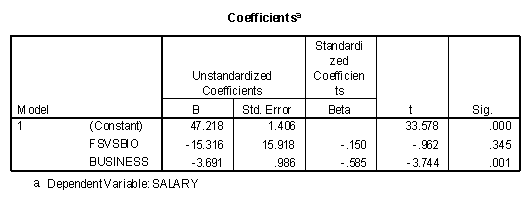
Note that the correlation coefficient between the two contrasts is zero. The correlation between the Business contrast and Salary is -.585 with a squared correlation coefficient of .342. This correlation coefficient has a significance level of .001. The correlation coefficient between the FSvsBio contrast and Salary is -.150 with a squared value of .023.
In this case entering Business or FSvsBio first makes no difference in the results of the regression analysis.
Entering both contrasts simultaneously into the regression equation produces the following ANOVA table.
Note that this table is identical to the two ANOVA tables presented in the previous section. It may be concluded that it does not make a difference what set of contrasts are selected when only the overall test of significance is desired. It does make a difference how contrasts are selected, however, if it is desired to make a meaningful interpretation of each contrast.
The coefficient table for the simultaneous entry of both contrasts is presented below.
Note that the "Sig." level is identical to the value when each contrast was entered last into the regression model. In this case the Business contrast was significant and the FSvsBio contrast was not. The interpretation of these results would be that the Business Department was paid significantly more than the Family Studies and Biology Departments, but that no significant differences in salary were found between the Family Studies and Biology Departments.
By carefully selecting the set of contrasts to be used in the regression with categorical variables, it is possible to construct tests of specific hypotheses. The hypotheses to be tested are generated by the theory used when designing the study.
If a categorical variable had six levels, five dummy coded contrasts would be necessary to use the categorical variable in a regression analysis. For example, suppose that a researcher at a headache care center did a study with six groups of four patients each (N is being deliberately kept small). The dependent measure is subjective experience of pain. The six groups consisted of six different treatment conditions.
| Group | Treatment |
|---|---|
| 1 | None |
| 2 | Placebo |
| 3 | Psychotherapy |
| 4 | Acupuncture |
| 5 | Drug 1 |
| 6 | Drug 2 |
An independent contrast is a contrast that is not a linear combination of any other set of contrasts. Any set of independent contrasts would work equally well if the end result was the simultaneous test of the five contrasts, as in an ANOVA. One of the many possible examples is presented below.
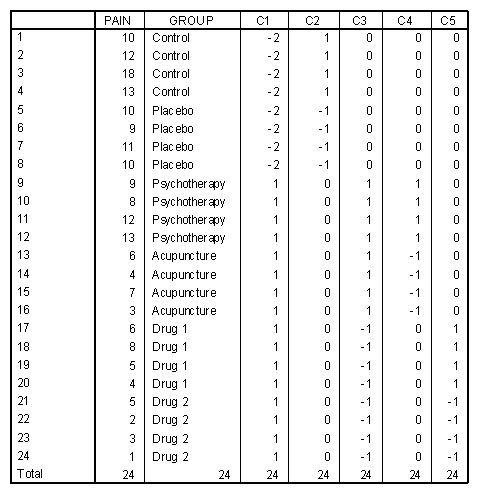
| Group | C1 | C2 | C3 | C4 | C5 | |
|---|---|---|---|---|---|---|
| None | 1 | 0 | 0 | 0 | 0 | 0 |
| Placebo | 2 | 1 | 0 | 0 | 0 | 0 |
| Psychotherapy | 3 | 0 | 1 | 0 | 0 | 0 |
| Acupuncture | 4 | 0 | 0 | 1 | 0 | 0 |
| Drug 1 | 5 | 0 | 0 | 0 | 1 | 0 |
| Drug 2 | 6 | 0 | 0 | 0 | 0 | 1 |
Application of this dummy coding in a regression model entering all contrasts in a single block would result in an ANOVA table similar to the one obtained using Means, ANOVA, or General Linear Model programs in SPSS.
This solution would not be ideal, however, because there is considerable information available by setting the contrasts to test specific hypotheses. The levels of the categorical variable generally dictate the structure of the contrasts. In the example study, it makes sense to contrast the two control groups (1 and 2) with the other four experimental groups (3, 4, 5, and 6). Any two numbers would work, one assigned to groups 1 and 2 and the others assigned to the other four groups, but it is conventional to have the sum of the contrasts equal to zero. One contrast that meets this criterion would be (-2, -2, 1, 1, 1, 1).
Generally it is easiest to set up contrasts within subgroups of the first contrast. For example, a second contrast might test whether there are differences between the two control groups. This contrast would appear as (1, -1, 0, 0, 0, 0). A third contrast might compare non-drug vs. rug treatment groups, groups 3 and 4 vs. groups 5 and 6 (0, 0, 1, 1, -1, -1). As can be seen, this would be a contrast within the experimental treatment groups. Within the non-drug treatment, a contrast comparing Group 3 with Group 4 might be appropriate (0, 0, 1, -1, 0, 0). Within the drug treatment conditions, a contrast comparing the two drug treatments would be the last contrast (0, 0, 0, 0, 1, -1). Combined, the contrasts are given in the following table.
| Group | C1 | C2 | C3 | C4 | C5 | |
|---|---|---|---|---|---|---|
| None | 1 | -2 | 1 | 0 | 0 | 0 |
| Placebo | 2 | -2 | -1 | 0 | 0 | 0 |
| Psychotherapy | 3 | 1 | 0 | 1 | 1 | 0 |
| Acupuncture | 4 | 1 | 0 | 1 | -1 | 0 |
| Drug 1 | 5 | 1 | 0 | -1 | 0 | 1 |
| Drug 2 | 6 | 1 | 0 | -1 | 0 | -1 |
The following table presents example data and dummy coded contrasts for this hypothetical study.
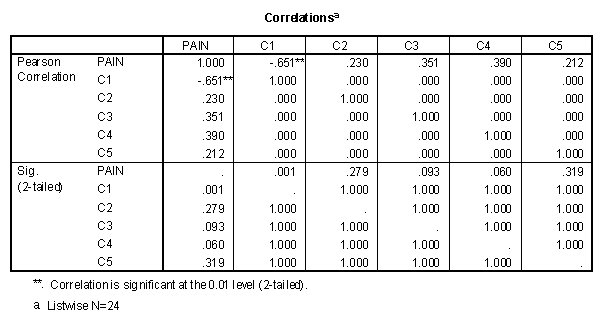
The correlation matrix of the five contrasts and the pain variable is presented below.
Note that the correlation coefficients between the five contrasts are all zero. This occurs because all groups have an equal number of subjects.
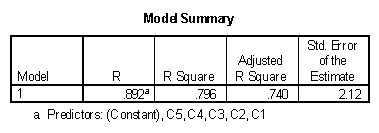
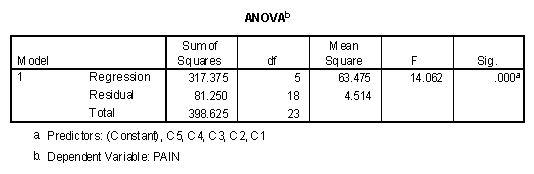
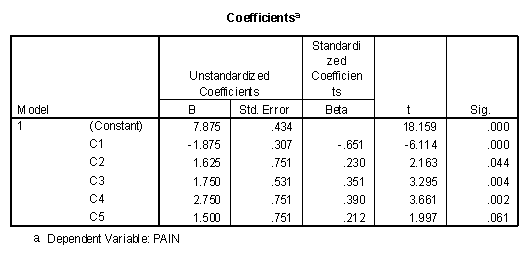
Using pain as the dependent variable and the five contrasts as the independent variables, the regression results tables entering all variables in block 1 are presented below.
Of major interest is the "Sig." column on the "Coefficients" table. Note that all contrasts are statistically significant except C5. This can be interpreted as: (1) The treatment conditions were more effective than the control conditions, (2) the two control conditions significantly differed from one another, with placebo more effective than control (3) The drug groups were more effective in reducing pain than the non-drug conditions (4) Acupuncture was significantly more effective than Psychotherapy (5) the two drug treatments were not significantly different from one another.
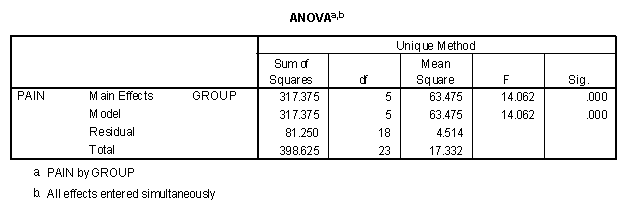
The output from the "General Linear Model, Simple Factorial" program in SPSS is presented below.
Note that it is for practical purposes identical to the ANOVA table produced using the multiple regression program with the dummy coded contrasts. In effect what the General Linear Model program does is to automatically select a set of contrasts and then perform a regression analysis with those contrasts. The General Linear Model program allows the user to specify a special set of contrasts so that an analysis like the one done with dummy coding of contrasts in multiple regression might be performed. It is left for the reader to explore SPSS for this ability.
In the original example data set for this chapter there were three obvious categorical variables, Gender, Rank, and Dept. Gender could be directly entered into the regression model. After dummy coding into two contrasts each, Rank and Dept could be directly entered into the regression model. Difficulties arise, however, when combinations of these categorical variables must be considered. For example, consider Gender and Dept. Rather than two groups and three groups, this combination of categorical variables must be considered as six groups, Male Family Studies, Female Family Studies, Male Biology, Female Biology, Male Business, and Female Business. Dummy coding these data would require five dummy coded contrasts. Three exist, one for Gender and two for Dept, but there is no accounting for the two additional contrasts. They will be the focus of the next topics, interaction effects.
Because everything works out much cleaner when equal sample sizes are assumed, this case will be presented first. The example data set has been reduced to twelve subjects, two for each combination of Gender and Dept. The reduced data set is presented below.
| Faculty | Salary | Gender | Dept |
|---|---|---|---|
| 7 | 45 | 0 | 1 |
| 11 | 34 | 0 | 1 |
| 14 | 42 | 0 | 2 |
| 15 | 42 | 0 | 2 |
| 9 | 59 | 0 | 3 |
| 12 | 53 | 0 | 3 |
| 4 | 30 | 1 | 1 |
| 10 | 47 | 1 | 1 |
| 8 | 42 | 1 | 2 |
| 2 | 58 | 1 | 2 |
| 5 | 50 | 1 | 3 |
| 6 | 49 | 1 | 3 |
The levels of Gender and Dept will now be combined to produce six groups.
| Salary | Gender | Dept | Group |
|---|---|---|---|
| 45 | 0 | 1 | 1 |
| 34 | 0 | 1 | 1 |
| 42 | 0 | 2 | 2 |
| 42 | 0 | 2 | 2 |
| 59 | 0 | 3 | 3 |
| 53 | 0 | 3 | 3 |
| 30 | 1 | 1 | 4 |
| 47 | 1 | 1 | 4 |
| 42 | 1 | 2 | 5 |
| 58 | 1 | 2 | 5 |
| 50 | 1 | 3 | 6 |
| 49 | 1 | 3 | 6 |
The situation is now analogous to the earlier case when the categorical variable had six levels.
A categorical variable with six levels can be dummy coded into five contrasts. The first three contrasts have already been discussed. The first of these contrasts will compare males with females and will comprise the Gender Main Effect. The next two will compare the salaries of the three departments over levels of gender and will be called the Department Main Effect. The dummy codes for these main effects are presented below.
| Salary | Group | Gender Main Effect | Department Main Effect | |
|---|---|---|---|---|
| 45 | 1 | 1 | 1 | 1 |
| 34 | 1 | 1 | 1 | 1 |
| 42 | 2 | 1 | 1 | -1 |
| 42 | 2 | 1 | 1 | -1 |
| 59 | 3 | 1 | -2 | 0 |
| 53 | 3 | 1 | -2 | 0 |
| 30 | 4 | -1 | 1 | 1 |
| 47 | 4 | -1 | 1 | 1 |
| 42 | 5 | -1 | 1 | -1 |
| 58 | 5 | -1 | 1 | -1 |
| 50 | 6 | -1 | -2 | 0 |
| 49 | 6 | -1 | -2 | 0 |
This is basically the same coding as discussed earlier, except it is simplified because of the equal number of subjects in each cell. It will later be demonstrated that the correlation coefficients between these dummy coded variables is zero.
Two additional dummy coded variables are needed to account for the categorical variable. These contrasts will comprise the Interaction Effect. In this case the easiest way to find the needed contrasts is to multiply the dummy coded contrast for gender times the dummy coded contrasts for Department. This has the result of changing the sign of the department contrasts for one gender but not the other. The results of this operation appear below.
| Salary | Group | Gender Main Effect | Department Main Effect | Interaction Effect | ||
|---|---|---|---|---|---|---|
| 45 | 1 | 1 | 1 | 1 | 1 | 1 |
| 34 | 1 | 1 | 1 | 1 | 1 | 1 |
| 42 | 2 | 1 | 1 | -1 | 1 | -1 |
| 42 | 2 | 1 | 1 | -1 | 1 | -1 |
| 59 | 3 | 1 | -2 | 0 | -2 | 0 |
| 53 | 3 | 1 | -2 | 0 | -2 | 0 |
| 30 | 4 | -1 | 1 | 1 | -1 | -1 |
| 47 | 4 | -1 | 1 | 1 | -1 | -1 |
| 42 | 5 | -1 | 1 | -1 | -1 | 1 |
| 58 | 5 | -1 | 1 | -1 | -1 | 1 |
| 50 | 6 | -1 | -2 | 0 | 2 | 0 |
| 49 | 6 | -1 | -2 | 0 | 2 | 0 |
The correlation matrix for this data set is presented below.
Note that the contrasts all have a correlation coefficient of zero among themselves. The contrasts will be entered into the regression equation predicting salary in three blocks. The first block will contain C1, the second will contain C2 and C3, while the third will contain C4 and C5. The results of this analysis are presented below.
Entering the contrasts in the opposite order has no effect on R Square Change.
The value for "F Change" and "Sig. F change" is different, however, because different error terms are employed in each case. In this subset of the data, none of the contrasts are significant. The interpretation of the main effects and interaction effects will be the topic of discussion of the next chapter.
Equal sample size is seldom achieved in the real world, even in the best-designed experiments. Unequal sample size makes the effects no longer independent. This implies that it makes difference in hypothesis testing when the effects are added into the model, first, middle, or last.
The same dummy coding that was applied to equal sample sizes will now be applied to the original data with unequal sample sizes. The simplest way to do this is to recode GENDER into C!, DEPARTMENT into C2 and C3, and compute C4 and C5 by multiplying corresponding contrasts into the new contrast. For example, C4 could be created by multiplying C1 * C2 and C5 could be created by multiplying C1 * C3. The data and dummy coded contrasts appear below.
The correlation matrix of the contrasts is presented below.
Note that the correlation coefficients between the contrasts are not zero. This has the effect of changing the value of R2 Change for a term depending upon when that term was entered into the model. This is illustrated by entering the two contrasts associated with Dept (C2 and C3) first, second, and last.
There are two different ways in which the main effect of Dept may be entered second in the regression model. The first is after Gender and is presented below.
As can be seen, the value of R2 change for adding C2 and C3 changes only slightly from .379 to .376. A slightly greater change in R2 change value is observed if the interaction contrasts (C4 and C5) are entered before the main effect of department.
Note that the value of R2 change is greater for Gender (C1) if it is entered last, rather than first.
Note that the value of R2 change is only changed slightly depending upon when it was entered into the model. The pattern of results of the significance tests would not change.
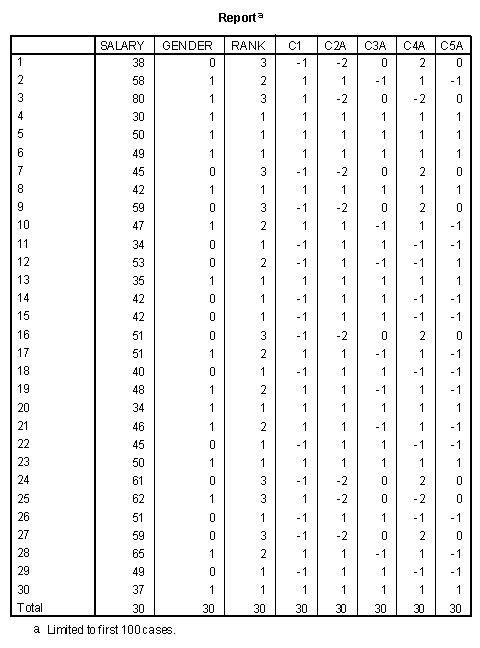
The dummy coded contrasts can be used like any other variables in a multiple regression analysis. In order to find the significance of the effect of Gender given Rank, Dept, Gender X Rank, Gender X Dept, Years, and Merit, the Rank and Gender X Rank effects must be created as dummy coded contrasts. In the following data file the Rank main effect consists of two contrasts: C2a contrasting Full professors with Assistant and Associate professors and C3a contrasting Assistant with Associate professors. The Gender X Rank interaction contrasts (C4a and C5a) are constructed by multiplying the Gender contrast (C1) times the two contrasts for the main effect for Rank.
| Gender | Rank | C1 | C2a | C3a | C4a | C5a |
|---|---|---|---|---|---|---|
| 0 | 1 | -1 | 1 | 1 | -1 | -1 |
| 0 | 2 | -1 | 1 | -1 | -1 | 1 |
| 0 | 3 | -1 | -2 | 0 | 2 | 0 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 2 | 1 | 1 | -1 | 1 | -1 |
| 1 | 3 | 1 | -2 | 0 | -2 | 0 |
The additional dummy coded variables are added to the data file in the following.
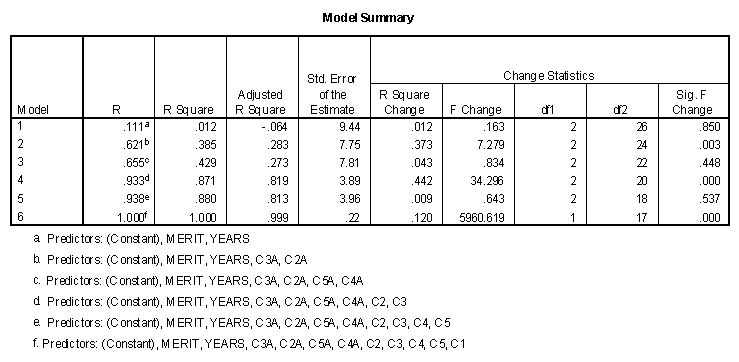
Salary is predicted in six blocks (only two are really needed) in the following multiple regression analysis. In a simplified analysis, the first block would contain all variables except Gender (C1) and the second would contain only Gender (C1).
As can be seen, the R2 change for Gender has increased to a value of .120 which is significant. The value of multiple R is not really 1.000, but very high, close to 1.000. For that reason the error variance is extremely small, resulting in significant effects. This illustrates the problem of fitting too few data points with too many parameters.
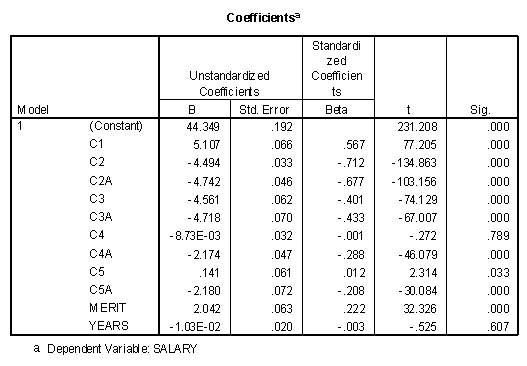
If all the effects mentioned above are entered into the model in a single block, the coefficients table appears as follows.
A has been described earlier, the "Sig." column is the significance level of that variable if it is entered last in the regression model. Since t2 = F, it is noted that 77.2052 is equal to 5960.619, within rounding error. In this case, every variable except C4 and Years is statistically significant.
The alert reader has probably noted that other interaction terms could be created and entered into the regression model. For example, four dummy coded contrasts could be created such that a Rank X Dept interaction could be found. Multiplying this by the Gender contrast (C1) would result in a three-way Gender X Rank X Dept interaction.
Although the dummy coding of variables in multiple regression results in considerable flexibility in the analysis of categorical variables, it can also be tedious to program. For this reason most statistical packages have made a program available that automatically creates dummy coded variables and performs the appropriate statistical analysis. In most cases the user is unaware of the calculations being performed in the computer program. This is the case with the General Linear Model program in SPSS.
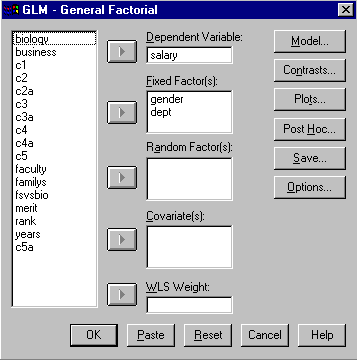
This program is selected in SPSS by Analyze/General Linear Model/GLM - General Factorial.... To perform the Gender by Department analysis discussed earlier in this section, enter Salary as the dependent measure and Gender and Dept as fixed factors. The screen should appear as follows.
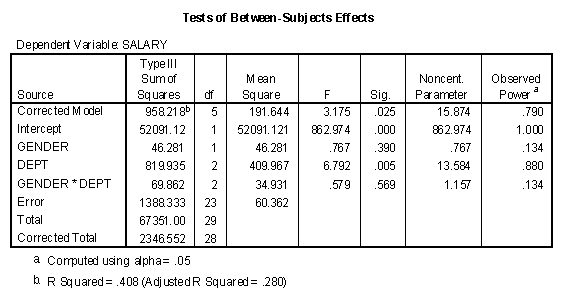
Click OK and the results are as follows.
Note that the "F" column and "Sig." column is identical to the results of the R2 change analysis presented earlier in this chapter if each of the effects is entered last. This is the meaning of the default "Type III Sum of Squares."
The interpretation of "effects," the result of the dummy coding of categorical variables, is the subject of the next chapter.
This chapter discussed how categorical variables with more than two levels could be used in a multiple regression prediction model. The procedure is called dummy coding and involves creating a number of dichotomous categorical variables from a single categorical variable with more than two levels. The text showed how any number of different coding systems would result in similar overall statistical decisions. It was also argued that some coding systems contain greater information about specific statistical decisions and are to be preferred over coding systems that provide less information. The usefulness of one type of coding system, that of main and interaction effects, was demonstrated when there were combinations of categorical variables. The similarity of this system of dummy coding and multifactor ANOVA was demonstrated.