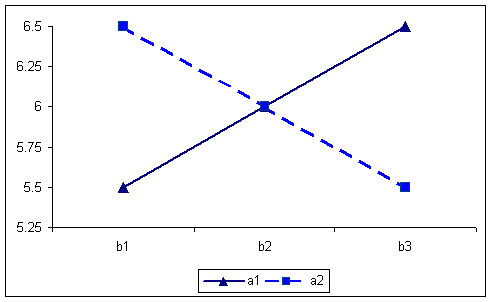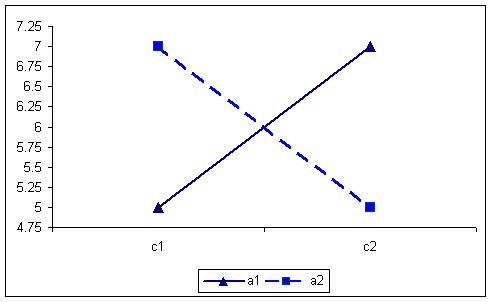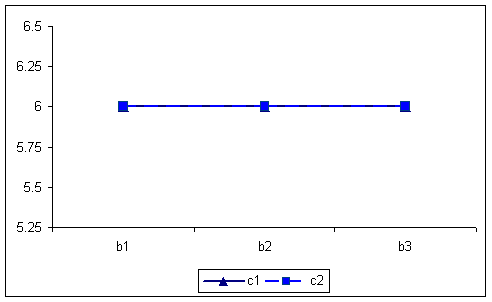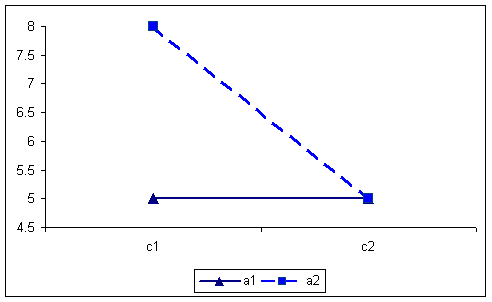Experimental design refers to the manner in which the experiment was set up. Experimental design includes the way the treatments were administered to subjects, how subjects were grouped for analysis, how the treatments and grouping were combined.
In ANOVA there is a single dependent variable or score. In Psychology the dependent measure is usually some measure of behavior. If more than one measure of behavior is taken, multivariate analysis of variance, or MANOVA, may be the appropriate analysis. Because the ANOVA model breaks the score into component parts, or effects, which sum to the total score, the one must assume the interval property of measurement for this variable. Since in real life the interval property is never really met, one must be satisfied that at least an approximation of an interval scale exists for the dependent variable. To the extent that this assumption is unwarranted, the ANOVA hypothesis testing procedure will not work.
In ANOVA there is at least one independent variable or factor. There are different kinds of factors; treatment, trial, blocking, and group. Each will be discussed in the following section. All factors, however, have some finite number of different levels. Each level is the same in either some quality or quantity. The only restriction on the number of levels is that there are fewer levels than scores, although in practice one seldom sees more than ten levels in a factor unless the data set is very large. It is not necessary that the independent variables or factors be measured on an interval scale. If the factors are measured on an (approximate) interval scale, then some flexibility in analysis is gained. The continued popularity of ANOVA can partially be explained by the lack of the necessity of the interval assumption for the factors.
Every writer of an introductory, intermediate, or advanced statistics text has his or her own pet notational system. I have taught using a number of different systems and have unabashedly borrowed the one to be described below from Lee (1975). In my opinion it is the easiest for students to grasp.
The dependent variable or score will be symbolized by the letter X. Subscripts (usually multiple) will be tagged on this letter to differentiate the different scores. For example, to designate a single score from a group of scores a single subscript would be necessary and the symbol Xs could be used. In this case X1 would indicate the first subject, X2 the second, X3 the third, and so forth.
When it is desired to indicate a single score belonging to a given combination of factors, multiple subscripts must be used. For example, Xabs would describe a given score for a combination of a and b. Thus, X236 would describe the sixth score when a=2 and b=3. Another example, X413, would describe the third score when a=4 and b=1.
Bolded capital letters will be used to symbolize factors. Example factors are A, B, C, ..., Z. Some factor names are reserved for special factors. For example, S will always refer to the subject factor, E will always be the error factor, and G will be the group factor.
Small letters with a numerical subscript are used to indicate specific levels of a factor. For example c1 will indicate the first level of factor C, while cc will indicate a specific level of factor C, but the level is unspecified. The number of levels of a factor is given by the unbolded capital letter of that factor. For example there are 1, 2, ..., C levels of factor C.
In an example experiment, let X, the score, be the dollar amount after playing WindowsTM Solitaire for an hour. In this experiment the independent variable (factor) is the amount of practice, called factor A. Let nine subjects each participate in one of four (A=4) levels of training. The first level, a1, consists on no practice, a2 = one hour of practice, a3 = five hours of practice, and a4 = twenty hours of practice. A given score (dollar amount) would be symbolized by Xas, where X35 would be the fifth subject in the group that received five hours of practice.
Treatments will be defined as quantitatively or qualitatively different levels of experience. For example, in an experiment on the effects of caffeine, the treatment levels might be exposure to different amounts of caffeine, from none to .0375 milligrams. In a very simple experiment there are two levels of treatment, none, called the control condition, and some, called the experimental condition.
Treatment factors are usually the main focus of the experiment. A treatment factor is characterized by the following two attributes (Lee, 1975):
1. An investigator could assign any of his experimental subjects to any one of the levels of the factor.
2. The different levels of the factor consist of explicitly distinguishable stimuli or situations in the environment of the subject.
In the solitaire example, practice time would be a treatment factor if the experimenter controlled the amount of time that the subject practiced. If subject's came to the experiment having already practiced a given amount, then the experimenter could not arbitrarily or randomly assign that subject to a given practice level. In that case the factor would no longer be considered a treatment factor.
In an experiment where subjects are run in groups, it sometimes is valuable to treat each group as a separate level of a factor. There might be, for example, an obnoxious subject who affects the scores of all other subjects in that group. In this case the second attribute would not hold and the factor would be called a group factor.
As described above, a group factor is one in which the subjects are arbitrarily assigned to a given group which differs from other groups only in that different subjects are assigned to it. If each group had some type of distinguishing feature, other than the subjects assigned to it, then it would no longer be considered as a group factor. If a group factor exists in an experimental design, it will be symbolized by G.
If each subject is scored more than once under the same condition and the separate scores are included in the analysis, then a trials factor exists. If the different scores for a subject were found under different levels of a treatment, then the factor would be called a treatment factor rather than a trials factor. Trials factors will be denoted by T.
Trials factors are useful in examining practice or fatigue effects. Any change in scores over time may be attributed to having previously experienced similar conditions.
If subjects are grouped according to some pre-existing subject similarity, then that grouping is called a blocking factor. The experimenter has no choice but to assign the subject to one or the other of the levels of a blocking factor. For example, gender (sex) is often used as a blocking factor. A subject enters the experiment as either a male or female and the experimenter may not arbitrarily (randomly) assign that individual to one gender or the other.
Because the experimenter has no control over the assignment of subjects to a blocking factor, causal inference is made much more difficult. For example, if in the solitaire experiment, the practice factor was based on a pre-existing condition, then any differences between the groups may be due either to practice or to the fact that some subjects liked to play solitaire, were better at the game and thus practiced more. Since the subjects are self-selected, it is not possible to attribute the differences between groups to practice, enjoyment of the game, natural skill in playing the game, or some other reason. It is possible, however, to say that the groups differed.
Even though causal inference is not possible, blocking factor can be useful. A factor that accounts for differences in the scores adds power to the experiment. That is, a blocking factor that explains some of the differences between scores may make it more likely to find treatment effects. For example, if males and females performed significantly different in the solitaire experiment, it might be useful to include sex as a blocking factor because differences due to gender would be included in the error variance otherwise.
In other cases blocking factors are interesting in their own right. It may be interesting to know that freshmen, sophomores, juniors, and seniors differ in attitude toward university authority, even though causal inferences may not be made.
In some cases the pre-existing condition is quantitative, as in an IQ score or weigh. In these cases it is possible to use a median split where the scores above the median are placed in one group and the scores below the median are placed in another. Variations of this procedure divide the scores into three, four, or more approximately equal sized groups. Such procedures are not recommended as there are better ways of handling such data (Edwards, 1985).
The unit factor is the entity from which a score is taken. In experimental psychology, the unit factor is usually a subject (human or animal), although classrooms, dormitories, or other units may serve the same function. In this text, the unit factor will be designated as S, with the understanding that it might be some other type of unit than subject.
The error factor, designated as E, is not a factor in the sense of the previous factors and is not included in the experimental design. It is necessary for future theoretical development.
Each factor in the design must be classified as either a fixed or random factor. This is necessary in order to find the correct error term for each effect. The General Linear Model program in SPSS requires that the user designate the type for each factor and place it in the correct analysis box.
A factor is fixed if (Lee, 1975)
1. The results of the factor generalize only to the levels that were included in the experimental design. The experimenter may wish to generalize to other levels not included in the factor, but it is done at his or her own peril.
2. Any procedure is allowable to select the levels of the factor.
3. If the experiment were replicated, the same levels of that factor would be included in the new experiment.
A factor is random if
1. The results of the factor generalize to both levels that were included in the factor and levels that were not. The experimenter wishes to generalize to a larger population of possible factor levels.
2. The levels of the factor used in the experiment were selected by a random procedure.
3. If the experiment were replicated, different levels of that factor would be included in the new experiment.
In many cases an exact determination of whether a factor is fixed or random is not possible. In general, the subjects (S) and groups (G) factors will always be a random factor and all other factors will be considered fixed. The default designation of General Linear Model will set the subjects factor as random and all other factors as fixed.
Some reflection on the assumption of a random selection of subjects may cause the experimenter to question whether it is in fact a random factor. Suppose, as often happens, subjects volunteered to participate in the experiment. In this case the assumptions underlying the ANOVA are violated, but the procedure is used anyway. Seldom, if ever, will all the assumptions necessary to do an ANOVA be completely satisfied. The experimenter must examine how badly the assumptions were violated and then make a decision as to whether or not the ANOVA is useful.
In general, when in doubt as to whether a factor is fixed or random, consider it fixed. One should never have so much doubt, however, as to consider the subjects factor as a fixed factor.
The following two relationships between factors describe a large number of useful designs. Not all possible experimental designs fit neatly into categories described by the following two relationships, but most do.
When two factors are crossed, each level of each factor appears with each level of the other factor. An "X" indicates a crossing relationship.
For example, consider two factors, A and B, were A is gender (a1 = Females, a2 = Males) and B is practice (b1 = none, b2 = one hour, b3 = five hours, and b4 = twenty hours). If gender was crossed with practice, A X B, then both males and females would participate in all four levels of practice. There would be eight groups of subjects including: ab11, females who had no practice, ab12, females who had one hour of practice, and so forth to ab24, males who practiced twenty hours. An additional factor may be added to the design, say handedness (C), where c1 = right handed and c2 = left handed. If the design of the experiment was A X B X C, then there would be sixteen groups, including abc231, left-handed males who practiced five hours.
If subjects (S) are crossed with treatments (A), S X A, each subject sees each level of the treatment conditions. In a very simple experiment such as the effects of caffeine on alertness (A), each subject would be exposed to both a caffeine condition (a1) and a no caffeine condition (a2). For example, using the members of a statistics class as subjects, the experiment might be conducted as follows. On the first day of the experiment the class is divided in half with one half of the class getting coffee with caffeine and the other half getting coffee without caffeine. A measure of alertness is taken for each individual, such as the number of yawns during the class period. On the second day the conditions are reversed, that is, the individuals who received coffee with caffeine are now given coffee without and vice-versa.
The distinguishing feature of crossing subjects with treatments is that each subject will have more than one score. This feature is sometimes used in referring to this class of designs as repeated measures designs. The effect also occurs within each subject, thus these designs are sometimes referred to as within subjects designs.
Crossing subjects with treatments has two advantages. One, they generally require fewer subjects, because each subject is used a number of times in the experiment. Two, they are more likely to result in a significant effect, given the effects are real. This is because the effects of individual differences between subjects is partitioned out of the error term.
Crossing subjects with treatments also has disadvantages. One, the experimenter must be concerned about carry-over effects. For example, individuals not used to caffeine may still feel the effects of caffeine on the second day, when they did not receive the drug. Two, the first measurements taken may influence the second. For example, if the measurement of interest was score on a statistics test, taking the test once may influence performance the second time the test is taken. Three, the assumptions necessary when more than two treatment levels are employed in a crossing subjects with treatments may be restrictive.
When a factor is a blocking factor, it is not possible to cross that factor with subjects. It is difficult to find subjects for a S X A design where A is gender. I generally will take points off if a student attempts such a design.
Factor B is said to be nested within factor if each meaningful level of factor B occurs in conjunction with only one level of A. This relationship is symbolized a B(A), and is read as "B nested within A". Note that B(A) is considerably different from A(B). In the latter, each meaningful level of A would occur in one and only one level of B. These types of designs are also designated as hierarchical designs in some textbooks.
A B(A) design occurs, for example, when the first three levels of factor B (b1 ,b3, and b3) appear only under level a1 of factor A and the next three levels of B (b4 ,b5, and b6) appear only under level a2 of factor A. Depending upon the labeling scheme, b4 ,b5, and b6 may also be called b1 ,b3, and b3, respectively. It is understood by the design designation that the b1 occurring under a1 is different from the b1 occurring under a2.
Nested or hierarchical designs can appear because many aspects of society are organized hierarchically. For example within the university, classes (sections) are nested within courses, courses are nested within departments, departments within colleges, and colleges within the university.
In experimental research it is also possible to nest treatment conditions within other treatment conditions. For example, suppose a researcher was interested in the effect of diet on health in hamsters. One factor (A) might be a high cholesterol (a1) or low cholesterol (a2) diet. A second factor (B) might be type of food, peanut butter (b1), cheese (b2), red meat (b3), chicken (b4), fish (b5), or vegetables(b6). Because type of food may be categorized as being either high or low in cholesterol, a B(A) experimental design would result. Chicken, fish, and vegetables would be relabeled as b1 ,b3, and b3, respectively, but it would be clear from the experimental design specification that peanut butter and chicken, cheese and fish, and red meat and vegetables, were qualitatively different, even though they all share the same label.
While any factor may possibly be nested within any other factor, the critical nesting relationship is with respect to subjects. If S is nested within some combination of other factors, then each subjects appear under one, and only one, combination of factors within which they are nested. These effects are often called the Between Subjects effects. If S is crossed with come combination of other factors, then each subject see all combinations of factors with which they are crossed. These effects are referred to as Within Subjects effects.
As mentioned earlier subjects are necessarily nested within blocking factors. Subjects are necessarily nested within the effects of gender and current religious preference, for example.
Treatment factors, however, may be nested or crossed with subjects. The effect of caffeine on alertness could be studied by dividing the subjects into two groups, with one receiving a beverage with caffeine and one group not. This design would nest subjects with caffeine and be specified as S(A), or simply A, as the S is often dropped when the design is completely between subjects.
If subjects appeared under both caffeine conditions, receiving caffeine on one day and no caffeine on the other, then subjects would be crossed with caffeine. The design would be specified as S X A. In this case the S would remain in the design.
A psychologist (McGuire, 1993) was interested in studying adults' memory for medical information presented by a videotape. She included one-hundred and four participants in which sixty-seven ranged in age from 18 to 44 years and thirty seven ranged in age from 60 to 82 years. Participants were randomly assigned to one of two conditions, either an organized presentation condition or an unorganized presentation condition. Following observation of the videotape, each participant completed an initial recall sequence consisting of free-recall and probed recall retrieval tasks. A probed recall is like a multiple-choice test and a free-recall is like an essay test. Following a one-week interval, participants completed the recall sequence again.
This experimental design provides four factors in addition to subjects (S). The age factor (A) has two level a1=young and a2=old and would necessarily be a blocking factor. The type of videotape factor (B) would be a treatment factor and would consist of two levels b1=organized and b2=unorganized. The recall method factor (C) would be a form of trials factor and would have two levels c1=free-recall and c2=probed recall. The forth factor (D) would be another trials factor where d1=immediate and d2=one week delay.
Each level of B appears with each level of A, thus A is crossed with B. Since each subject appears in one and only one combination of A and B, subjects are nested within A X B. That is, each subject is either young or old and sees either an organized or unorganized videotape. The design notation thus far would be S ( A X B ).
Each type of recall (C) was done by each subject at both immediate and delayed intervals (D). Thus subjects would be crossed with recall method and interval. The complete design specification would be S ( A X B ) X C X D. In words this design would be subjects nested within A and B and crossed with C and D.
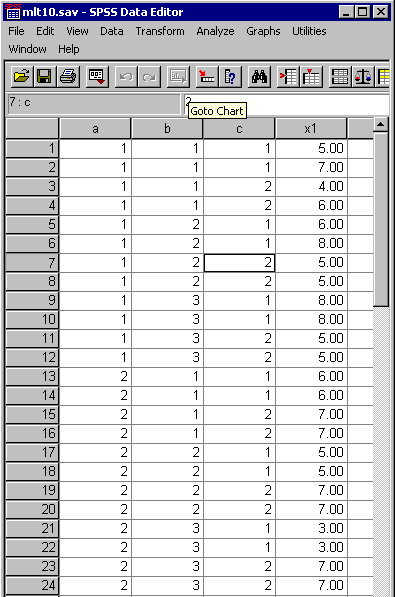
In preparation for entering the data into a data file, the design could be viewed in a different perspective. Listing each subject as a row and each measure as a column, the design would appear as follows:
| Immediate | One Week Later | |||||
|---|---|---|---|---|---|---|
| Age | Videotape | Subject | Free | Probed | Free | Probed |
| Young | Organized | s1 | ||||
| s2 | ||||||
| Unorganized | ... | |||||
| s67 | ||||||
| Old | Organized | s68 | ||||
| s69 | ||||||
| Unorganized | ... | |||||
| s104 | ||||||
In this design, two variables would be needed. One to classify each subjects as either young or old, and one to document which type of videotape the subject saw. In addition to the classification variables, each subject would require four variables to record the two types of measures taken at the two different times.
A score taken from the design presented above could be represented as Xabscd. For example, the immediate probed test score taken from the third subject in the old group who viewed an organized videotape would be X21312.
The Lombard effect is a phenomenon in which a speaker or singer involuntarily raises his or her vocal intensity in the presence of high levels of sound. In a study of the Lombard effect in choral singing (modified from Tonkinson, 1990), twenty-seven subjects, some experienced choral singers and some not, were asked to sing the national anthem along with a choir heard through headphones. The performances were recorded and vocal intensity readings from three selected places in the song were obtained from a graphic level recorder chart. Each subject sang the song four times: with a none, or a soft, medium, or loud choir accompaniment. After some brief instructions to resist increasing vocal intensity as the choir increased, each subject again sang the national anthem four times with the four different accompaniments. The order of accompaniments was counterbalanced over subjects.
In this design, there would be four factors in addition to subjects. Subjects would be nested within experience level (A), with a1=inexperienced and a2=experienced choral singers. This factor would be a blocking factor. Subjects would be crossed with instructions (B), where b1=no instructions and b2=resist Lombard effect. In addition, subjects would be crossed with accompaniment (C) and place in song (D). The accompaniment factor would include four levels c1=soft, c2=medium, c3=loud, and c4=none. This factor would be considered a treatment factor. The place in song factor could be considered a trial factor and would have three levels.
The experimental design could be written as S(A)X B X C X D. In words, subjects were nested within experience level and crossed with instructions, accompaniment, and place in song. In this design, one variable would be needed for the classification of each subject and twenty-four variables would be needed for each subject, one for each combination of instructions, accompaniment, and place in song. The design could be written:
| No Instructions | Resist Lombard Effect | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Experience | Subject | Soft | Medium | Loud | None | Soft | Medium | Loud | None |
| 1 | 1 | ||||||||
| 1 | ... | ||||||||
| 1 | 14 | ||||||||
| 2 | 15 | ||||||||
| 2 | ... | ||||||||
| 2 | 27 | ||||||||
From the Springfield News-Leader, March 1, 1993:
images of beauty such at those shown by Sports Illustrated's annual swimsuit issue, are harmful to the self-esteem of all women and contribute to the number of eating disorder cases in the U. S., says a St. Louis professor who researches women's health issues.
In a recent study at Washington University, two groups of women - one with bulimia and one without - watched videotapes of SI models in swimsuits.
Afterwards, both groups reported a more negative self-image than they did before watching the tape, describing themselves as "feeling fat and flabby" and "feeling a great need to diet."
The experiment described above has a number of inadequacies, the lack of control conditions being the most obvious. The original authors, unnamed in the article, may have designed a much better experiment than is described in the popular press. In any case, this experiment will now be expanded to illustrate a complex experimental design.
The dependent measure, apparently a rating of "feeling fat and flabby" and "feeling a great need to diet", will be retained. In addition, two neutral questions will be added, say "feeling anxious" and "feeling good about the environment." These four statements will be rated by all subjects, thus subjects will be crossed with ratings. The first two statements deal with body image and diet and the last two do not, thus they will form a factor in the design (called D). Since the statements within each of body image factor share no similarity across levels of D, these statements (A) are nested within D. For example, the rating of "feeling a great need to diet" and "feeling good about the environment" share no qualitative relationship. At this point the design may be specified as S X A(D).
Suppose the researcher runs the subjects in groups of six to conserve time and effort, thus creating a groups (G) factor. In addition to the two groups, with bulimia and without (B), suppose the subjects viewed one of the following videotapes (V): SI models, Rosanne Barr, or a show about the seals of the great northwest. Assuming that all the subjects in each level of group either had bulimia or did not, then the design could be specified as S(G(B X V)).
The factor B is crossed with V because each level of B appears with each level of V. That is, subjects with and without bulimia viewed all three videotapes. Because each group viewed only a single videotape and was composed of subjects either with bulimia or without, the groups factor is nested within the cross of B and V. Because subjects appeared in only one group, subjects are nested within groups.
Combining the between subjects effects, S(G(B X V)), and the within subjects effects, A(D), yields the complete design specification S(G(B X V)) X A(D).
It is important to be able to determine the number of subjects and the number of measures per subject for practical reasons, namely, is the experiment feasible? After listening to a student propose an experiment and a little figuring, I remarked "according to my calculations, you should be able to complete the experiment sometime near the middle of the next century." If an experimenter is limited in the time a subject is available, then the number of measures per subject is another important consideration.
To determine the number of subjects, multiply the number of levels of the between subjects factor together. In the previous example, S = 6 because the subjects were run in groups of six. Let G=4, or there be four groups of six each of combinations of bulimia and videotape. Since there were two levels of bulimia, B=2, and three levels of videotape, V=3. Since S(G(B X V)), then the total number of subjects needed would be S * G * B * V or 6*4*2*3 or 144. Since half of the subjects must have bulimia, the question of whether or not 72 subjects with bulimia are available must be asked before the experiment proceeds.
To find the number of measures per subject, multiply the number of levels of the within subjects factors together. In the previous example A(D), where A=2 and D=2, there would be A * D or 2 * 2 or 4 measures per subject.
A few rules simplify setting up the data matrix. First, each subject appears on a single row of the data matrix. Second, each measure or combination of within subjects factors appears in a column of data. Third, each subject must be identified as to the combination of between subjects factors which he or she appears.
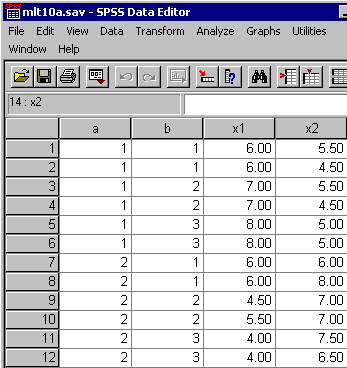
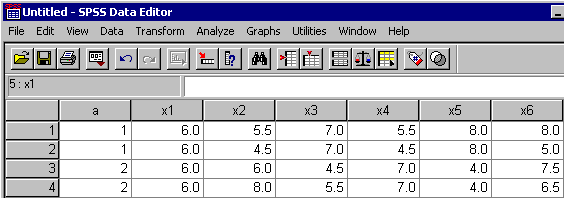
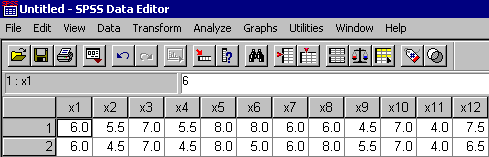
A example SPSS data file for an A x B x C design appears below:
A example SPSS data file for an S(A x B) x C design appears below:
A example SPSS data file for an S(A) x B x C design appears below:
A example SPSS data file for an S x A x B x C design appears below:
In the self-image experimental design example, since there would be 144 subjects in the experiment, there would be 144 rows of data. Each subject would be identified as to the level of G, B, and V to which she belonged. For example, a subject who appeared under g3 of b1 and v4 would be labeled as 3 1 4. Since there are four measures per subject, these would appear as columns in addition to the identifiers. An example data matrix might appear as follows. In this example, the level of G is in the first column, B in the second, and V in the third. The four combinations of within subjects factors appear next as ad11 ad12 ad12 ad22.
It is fairly easy to design complex experiments. Running the experiments and interpreting the results are a different matter. Many complex experiments are never completed because of such difficulties. This is from personal experience.
This chapter will focus on four designs that serve the same function, to test the effects of three factors simultaneously. The designs that will be studied include:
S X A X B X C
S ( A ) X B X C
S ( A X B ) X C
A X B X C
Since the naming of the factors is arbitrary, these designs include all possible three factor designs. In a departure from the last few chapters, the similarities of these designs will first be studied, followed by the differences. The advantages and disadvantages of each will be then be presented.
The function of the four designs given above is to test for the reality of three kinds of effects, main, two-way interaction, and three-way interaction. Although the first two have been described in detail in earlier chapters, the different forms of the effects will be discussed. The three-way interaction will be discussed in detail.
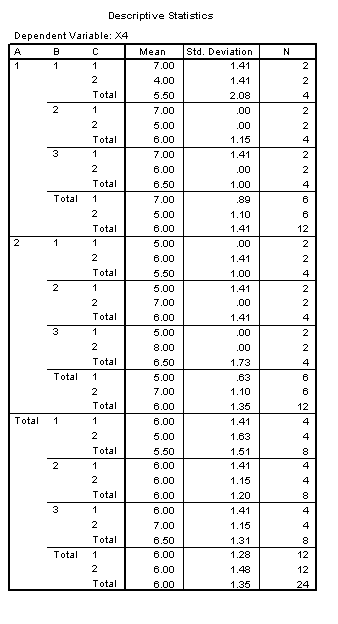
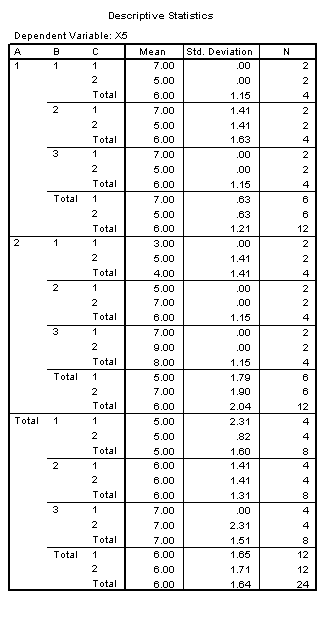
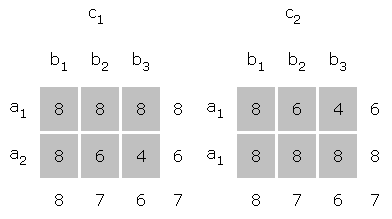
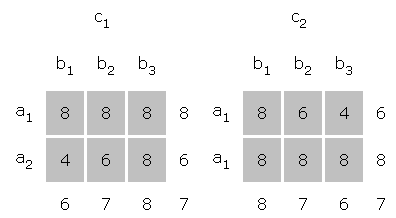
A study of effects begins with a table of means. This table might be constructed by averaging over subjects in any number of ways, depending upon the design. An example follows.
Main effects are found in a manner analogous to finding main effects in a two factor design, except that the data must be collapsed over two other effects rather than one. In the case of a three factor experiment, there will be three main effects, one for each factor, A, B, and C.
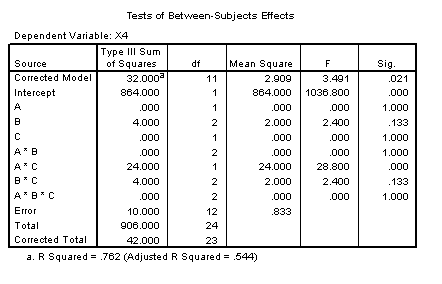
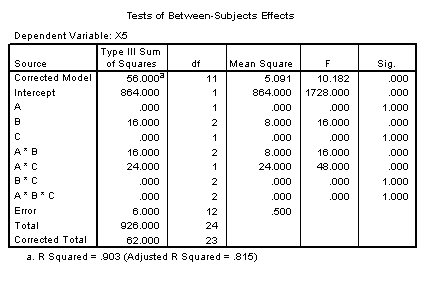
For example, in order to find the main effect of factor A, one must find the mean of each level of A, collapsing over levels of B and C. In the above example a.. = ( a11 + a12 + ... + ABC) / BC. Where a=1, B=3, and C=2, 1.. = ( 111 + 112 + 121 + 122 + 131 + 132 ) / 6 = ( 5 + 5 + 5 + 6 + 7 + 8 ) / 6 = 6. Likewise, 2.. = 6 and there would be no main effect of A, because these values are similar.
In a like manner, .1. = .2. = .3. = 6 and there would be no main effect of B. From the table above it can be seen that ..1 = ..2 = 6 and there would be no main effect of C. Thus, this table is an example of a three factor experiment where no main effects would be found.
Each combination of two factors produces a two-way interaction by collapsing over the third factor. The three two-way interactions are interpreted just like the single two-way interaction would be in an A X B design.
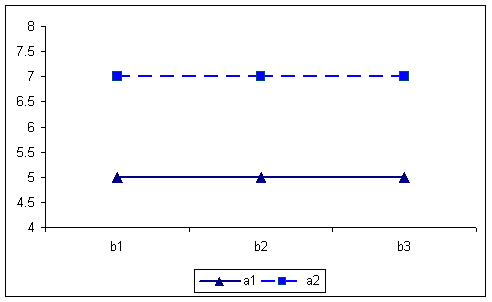
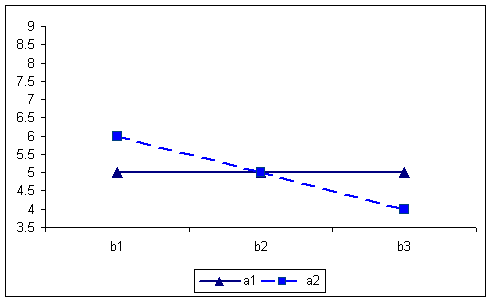
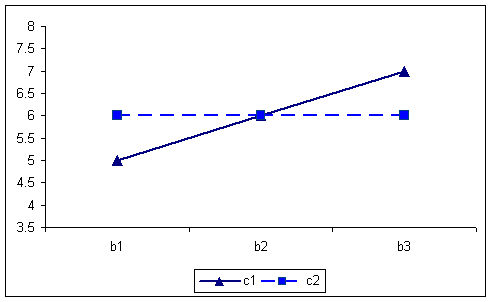
By collapsing over the C factor, the AxB interaction yields the following table and graph. Note that an AxB interaction is present because the simple main effect of B does changes over levels of A, in one instance increasing with B and the other decreasing. This table also clearly illustrates the lack of an A or B main effect.
A X B table of means for first example. 5.566.56 6.565.56 6666
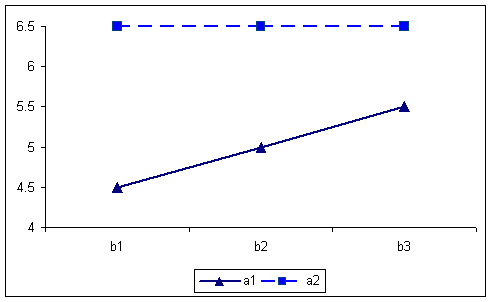
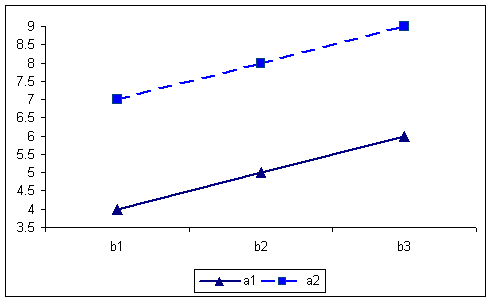
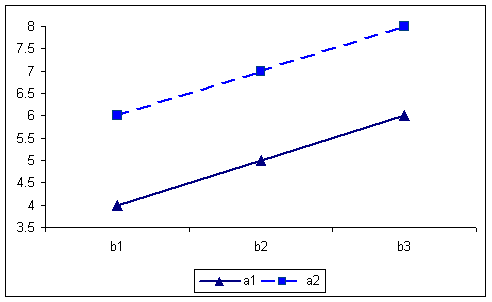
By collapsing over the B factor, the AxC interaction produces the following table and graph. The cells in the table reproduce the numbers that appeared as row means in the full table. In this case there could be an AxC interaction present.
A X C table of means for first example. 576 756 666
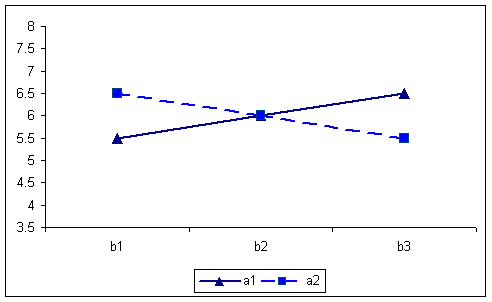
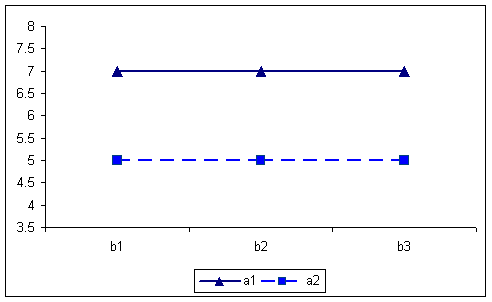
By collapsing over the A factor, the BxC table and graph are produced. The numbers in the graph appear as row means on the separate tables in the original data. In this case the interaction is absent.
B X C table of means for first example 6666 6666 6666
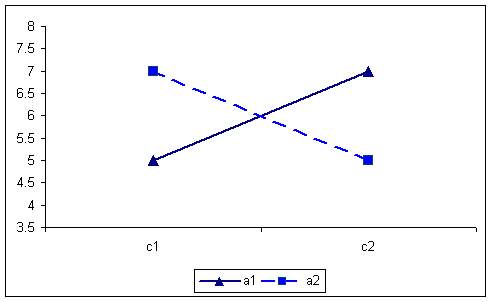
The three-way interaction, AxBxC, is a change in the simple two-way interaction over levels of the third factor. A simple two-way interaction is a two-way interaction at a single level of a third factor. For example, going back to the original table of means in this example, the simple interaction effect of AB at c1 would be given in the means in the left-hand boxes. The same simple interaction at c2 would be given in the right-hand boxes.
A change in the simple two-way interaction refers a change in the relationship of the lines. If in both simple two-way interactions the lines were parallel, no matter what the orientation, there would be no three-way interaction. Similarity, if the lines in the simple two-way interactions intersected at the same angle, again no matter what the orientation, there would be no three-way interaction.
In the case of the example data, graphed below, the orientation of the lines comprising the simple interactions changes from parallel to non-parallel from one graph to the other. In this case a three-way interaction would exist. It may or may not be significant depending upon the size of the error term.
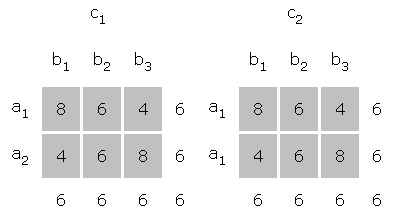
The following table of means was constructed such that all effects would be significant, given that the error terms were small relative to the size of the effects.
The A X B interaction in table and graph form follow:
A X B Interaction 4.555.55 6.56.56.56.5 5.55.7566
The same is now done for the A X C interaction:
A X C Interaction with all effects significant. 555 856.5 5.555.75
In a similar fashion the table and graph for the B X C interaction:
B X C Interaction with all effects significant. 5.56.57.56.5 5.554.55 5.55.7565.75
Finally the table of means is repeated and graph of the three-way interaction is given.
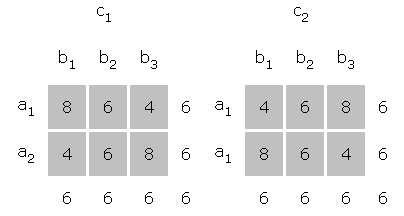
Selecting a somewhat arbitrary combination of effects, one could ask what table of means could produce a combination of effects such that B, AxC, and BxC would possibly be significant and all other effects would not be significant. The following tables are one solution.
The presence of a B main effect and the lack of an A main effect and AxB interaction is seen in the following table and graph.
AxB table of means with B, AxC, and BxC 5.566.56 6.565.56 6666
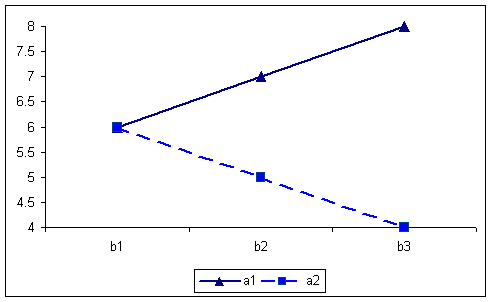
The AxC interaction is seen in the following.
A X C Interaction 576 756 666
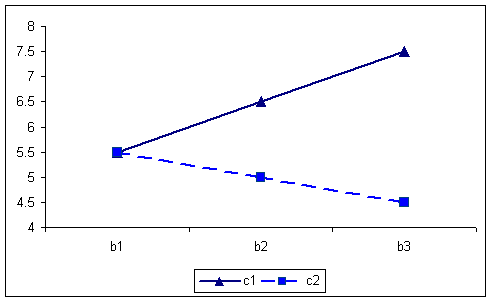
The BxC interaction is seen in the following.
B X C Interaction 5676 6666 5.566.56
The AxBxC three-way interaction is not significant because the simple interaction of AxB does not change over levels of C. In this case the lines are parallel in both cases.
Because a three-way interaction does not always appear as intuitive to students, two additional examples three-way interactions are now given. In the first case, the three-way interaction is not significant because the relationships between the lines in the simple interactions do not change. In the second example, only the three-way interaction is significant.
The reader should verify that in the above example there might be a significant main effect of B, an AxB interaction, and an AxC interaction, but no other effects could be significant.
In the above example, only the three-way interaction could be significant. There could be no other significant effects.
In its full form, the experiment designed to test the Lombard effect in choral singers neatly fulfill this design. Factor A was choral singing experience - None, Some, or Lots. Each subject sang the national anthem twice, Factor B, the first time with no instructions and the second with instructions to try to control vocal intensity. Singing loudness (in decibels) was measured at three different points (Factor C) in the song.
The data has been presented in its full form in a previous chapter (Design S X A X B), so it is not necessary to present it again. The General Linear Model commands necessary to do the analysis are given below.
The means and standard deviations are presented first.
The results of the hypothesis tests from the preceding set of commands is presented below in its full form.
From the preceding analysis the results are reasonably clear. Main effects were found for the INSTRUCT and PLACE factors. When instructed, the singers sang with less intensity. In different places in the song the singers also sang with different intensity levels over both levels of instructions.
The significant interactions of EXPER x PLACE and INSTRUCT x PLACE are best seen in the three-way interaction, even though the three-way interaction was not significant. The graph of the EXPER x INSTRUCT x PLACE interaction is presented below.
From the above graphs it can be seen that the more experienced the singer, the more loudly he or she sang. In addition, experienced singers sang relatively more loudly than inexperienced singers at song positions 2 and 3. Also, the instructions to sing at an even level seemed to work best at position 2, combined over all groups.
For an explanation of what all this means, it is perhaps best to refer to the original author (Tonkinson,1990, p. 25)
The original problem was: Is the Lombard effect, to a significant degree, and unconscious response in choral singing at different levels of experience and training, and can it be consciously avoided. Most of the choral singers in this study, regardless of experience, tended to succumb to a Lombard effect when faced with increasing loss of auditory feedback. They were, however, able to control the level of vocal intensity with some brief instructions. It appears that simple training in awareness would be enough for a member of an amateur choir to begin regulating the intensity of their voice in a healthy manner.
This chapter explored the topics of experimental design and analysis of three and more factor experiments. The different kind of factors, treatment, blocking, trial, group, and subject were first discussed, followed by a discussion of how factors could be related to one another (crossed or nested). Based on the experiment design, the data matrix would be set up and analyzed differently.
The discussion of experimental designs was followed by a discussion of types of effects that result from the various experimental designs. A major focus to the chapter was the interpretation of two and three-factor interactions using graphs of means.