It has been said that some texts are written to impress one's colleagues and others are written for students. This one is written for students. It is neither a mathematical treatise nor a cookbook. Instead of complicated mathematical proofs I have attempted to write a book about mathematical ideas. I have substituted examples for proofs and require that the reader "believe!" on more than one occasion. The result is a text that can be understood by students. A grasp of the fundamental ideas presented in this text will prepare the student for a much more thorough treatment of statistics in a later course.
I have titled my text Introductory Statistics: Concepts, Models, and Applications for a reason. The order of the words in the subtitle is critical. I believe that without a fundamental understanding of the "big picture" the student will get lost in the details of statistics. What I have tried to do with this text is to present a conceptual framework around the term "models". Rather than attempting to provide many applications and examples and then asking the student to deduce the concept, I have attempted to introduce the concept and then provide a few examples of the application of the concept.
The publication of this text fulfills a vision that started over twenty-three years ago. In that vision I would write a statistics text that would be distributed and read on a computer. I started writing my text because I was not satisfied with the contents of the statistics texts at that time. My text was going to be different. It was going to explain the underlying concepts of statistics, explore controversial issues, and eliminate almost all computational formulas. I required my students to purchase statistical calculators and showed them how to use statistical packages on the university's mainframe computer to do much of the computation.
I began my vision on a computer that I soldered together and that used a cassette tape player to store the document. I soon learned how to generate unique assignments for each student. I did so because I didn't see how a student could get much benefit from frantically copying his neighbor's homework assignment.
I wrote the text and had the university bookstore print it and distribute it to my students. As computers changed, so did the word processor, graphics generator, statistical package, statistical calculator, and printer used to generate the text. The text went through many iterations, each an improvement. I found that even slight changes, like moving the chapter on theoretical probability distributions immediately after the chapter on frequency polygons rather than after the chapter on statistics caused a ripple effect throughout the text. Creating a user interface for the normal curve table eliminated the need for the table and the text that described how to use the table. This also had a ripple effect in later chapters, with the result that it is possible to describe conceptually what is occurring without the need to bog the student down in mindless details about how to do it.
In the early 1990's I tried distributing the text as a WordPerfect document using FTP (an early means of transferring files). It was too much trouble for anyone to download the document, access it using the right version of the word processor, and then print it. In addition, it was really hard to publicize its availability.
When the World Wide Web (WWW) took off in the mid 1990's, I converted the material yet another time, this time to HTML. I made the text freely available to anyone who was connected to the WWW and took steps to insure that its delivery system was adequate. I advertised the availability of the text on search engines. I explored the possibility of using simulations and interactive exercises to illustrate statistical principles. My feeling was what good was a book if no one reads it. It was my gift to the world.
For this edition I have converted the text yet another time, this time to XML. I wish to thank my publisher, Alex von Rosenberg for believing in the text and encouraging me to update the material and means of presentation. This time the text is no longer free, but additions have been made to enhance the value of the text. I was concerned about the viability of the text when I am no longer associated with the university. I no longer have such concerns.
From the very beginning, this text was designed to take advantage of technological advances to compute statistics. In many ways it is easier to write and teach computational procedures than it is to present the underlying logic of the method. I have selected what I consider to be the more demanding route for the student.
If statistics involves building models and models are simplifications of the world, then building models necessarily involves simplifying assumptions. These assumptions may be explicit, as in the assumption that the residuals in a regression are normally distributed, or they may be implicit, as in the assumption that the numbers have meaning. It is critical that the assumptions made when constructing models be understood and be reasonable. On the other hand, it is just a wrong to become slaves to the assumptions, demanding that every assumption be fully satisfied, because they never will be.
In this text I spend considerably more time than other texts attempting to make explicit some of the implicit assumptions underlying the use of numbers. For example, I spend considerable time and effort developing measurement theory. In this I attempt to explore some of the nuances and issues surrounding meaning and numbers.
The chapter on probability theory was one of the most difficult to write. The treatment given this topic in most introductory statistics texts is either bogged down in set theory and combinatorial mathematics or simply glossed over. I have attempted to integrate probability theory conceptually into the model-building schema presented in an earlier chapter. Rather than taking a divisive position as to the correct manner in which probabilities should be employed, I have tried to present the material in such a way that probabilities become a useful tool to help us make decisions about the world no matter what the theoretical background.
In this text I present classical hypothesis testing, not necessarily because I see it as the one true path to knowledge, but because it has proven to be a useful tool in assisting people to make decisions about which effects are real and which could be due to chance. It would be almost impossible to underestimate the influence classical hypothesis testing has had on the social sciences. I have real reservations, however, about becoming slaves to the almighty .05 level of significance and present a fairly lengthy discussion of the importance on considering the costs of various errors when doing hypothesis tests.
This course is designed for individuals who desire knowledge about some very important tools used by the Behavioral Sciences to understand the world. Some degree of mathematical sophistication is necessary to understand the material in this course. The prerequisite for this text is a first course in Algebra, preferably at the college level. Students have succeeded with less, but it requires a greater than average amount of time and effort on the part of the student. If there is any doubt about whether or not the reader can follow the mathematics, it is recommended that the chapter on the Review of Algebra be attempted. If successful, then the material in the rest of the book will most likely also be successfully mastered.
Emphasis has been placed in several different directions during the past two decades with respect to the teaching of statistics in the behavioral sciences. The first, during the 1950's and perhaps early 1960's saw a focus on computation. During this time, large electro-mechanical calculators were available in many statistics laboratories. These calculators usually had ten rows and ten columns of number keys, and an addition, subtraction, multiplication, and division key. If one was willing to pay enough money, one could get two accumulators on the top; one for sums and one for sum of squares. They weighed between 50 and 100 pounds, filled a desktop, made a lot of noise, and cost over $1000. Needless to say, not very many students carried one around in their backpack.
Because the focus was on computation, much effort was made by the writers of introductory textbooks on statistics to reduce the effort needed to perform statistical computations using these behemoths. This was the time period during which computational formulas were developed. These are formulas that simplify computation, but give little insight into the meaning of the statistic. This is in contrast to definitional formulas, that better describe the meaning of the statistic, but are often a nightmare when doing large-scale computation. To make a long story short, students during this phase of the teaching of introductory statistics ended up knowing how to do the computations, but had little insight into what they were doing, why they did it, or when to use it.
The next phase was a reaction to the first. Rather than computation, the emphasis was on meaning. This was also the time period of the "new math" in grade and high schools, when a strong mathematical treatment of the material was attempted. Unfortunately, many of the students in the behavioral sciences were unprepared for such an approach and ended up knowing neither the theory nor the computational procedure.
Calculators available during this time were electronic, with some statistical functions available. They were still very expensive, over $1000, and would generally not fit in a briefcase. In most cases, the statistics texts still retained the old computational formulas.
The current trend is to attempt to make statistics as simple for the student as possible. An attitude of "I can make it easier, or more humorous, or flashier than anyone else has in the past" seems to exist among many introductory statistics textbooks. In some cases this has resulted in the student sitting down for dinner and being served a hot fudge sundae. The goal is admirable, and in some cases achieved, but the fact remains that the material, and the logic underlying it, is difficult for most students.
My philosophy is that the statistical calculator and statistical computer packages have eliminated the need for computational formulas; thus they have been eliminated from this text. Definitional formulas have been retained and the student is asked to compute the statistic once or twice "by hand." Following that, all computation is done using the statistical features on the calculator.
This is analogous to the square root function on a calculator. How many times do people ever use the complex algorithm they learned in high school to find a square root? Seldom or never. It is the argument of the present author that the square root procedure should be eliminated from the mathematics classroom. It gives little or no insight into what a square root is or how it should be used. Since it takes only a few minutes to teach a student how to find a square root on a calculator, it is much better to spend the remaining classroom time discussing the meaning and the usefulness of the square root.
In addition, an attempt has been made to tie together the various aspects of statistics into a theoretical whole by closely examining the scientific method and its relationship to statistics. In particular, this is achieved by introducing the concept of models early in the course, and by demonstrating throughout the course how the various topics are all aspects of the same approach to knowing about the world.
It is not unusual to hear a student describe their past experience with a mathematics course with something like the following: "I had an algebra class 10 years ago, I hated it, I got a 'D' in it, I put this course off until the last possible semester in my college career...". With many students, statistics is initially greeted with mixed feelings of fear and anger. Fear because of the reputation of mathematics courses, anger because the course is required for a major or minor and the student has had no choice in its selection. It is my feeling that these emotions inhibit the learning of the material. It is my experience that before any real learning may take place the student must relax, have some success with the material, and accept the course. It is the responsibility of the instructor to deal with these negative emotions. If this is not done, the course might just as well be taught by a combination of books and computers.
Another difficulty is sometimes encountered by the instructor of a statistics course is the student who has done very well in almost all other courses, and has a desire to do very well in a statistics course. In some cases it is the first time that the material does not come easily to the student, with the student not understanding everything the instructor says. Panic sets in, tears flow, or perhaps the student is simply never seen in a statistics classroom again.
The student must be willing to accept the fact that a complete understanding of statistics may not be obtained in a single introductory course. Additional study, perhaps graduate work, is necessary to more fully grasp the area of statistics. This does not mean, however, the student has achieved nothing of value in the course. Statistics may be understood at many different levels; it is the purpose of this text to introduce the material in a manner such that the student achieves the first level.
A two-variable statistical calculator is necessary to follow along with many of the computational procedures presented in this text. Generally, if a calculator has two buttons, labeled
![]() and
, it will suffice for the text. No particular brand or model of calculator is specified and it is the duty of the student to translate the general instructions included in this text into specific sequences of key presses for a particular calculator. Thus a manual or at least an instructional sheet is an absolute necessity. More powerful, graphically oriented calculators will also work for the text, but it has been the experience of the author that unless the student knows and loves such a calculator, the additional complexity is a distraction to understanding the basic concepts presented in the text.
and
, it will suffice for the text. No particular brand or model of calculator is specified and it is the duty of the student to translate the general instructions included in this text into specific sequences of key presses for a particular calculator. Thus a manual or at least an instructional sheet is an absolute necessity. More powerful, graphically oriented calculators will also work for the text, but it has been the experience of the author that unless the student knows and loves such a calculator, the additional complexity is a distraction to understanding the basic concepts presented in the text.
Unlike the selection of a statistical calculator, where any number of different brands and models will work, this text uses a single statistical package, SPSS, to demonstrate computational procedures and presentation of results. SPSS is a copyrighted computer program developed by SPSS, Inc. (http://www.spss.com) and is widely used and available at both the academic and business institutions. It is most likely available at your institution.
The purchase of SPSS for use on home computers can be done a number of different ways. Some educational institutions have site licenses with SPSS, Inc. that permit students to obtain personal copies of the full version at a nominal cost. If an institution does not have such a license, then it is often possible to purchase a "Student" version at a greatly discounted cost. The student version is basically a stripped down copy of the full version, but will suffice for this text. A "Graduate Student" version, adding statistical functions and capabilities to the student version, may also be available at a higher cost. In general the additional capabilities of the graduate student or full versions do not add much additional complexity from the user's perspective and are preferred if available at reasonable cost.
If the different versions described above: student, graduate student, and full, were not confusing enough, SPSS has iterated through numerous numbered versions. This text was written using the most current version, 10.0, available to the author. The changes from versions 8.0 and 9.0 to 10.0 have been fairly minor and readers should be able to follow along if they do not have the most current version.
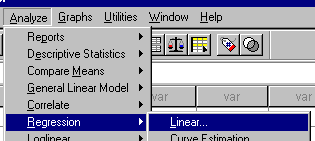
Throughout the text it is often necessary to document the procedure to compute a statistic using the SPSS statistical package. For example, in the following screen, the user has clicked on
"Analyze", followed by "Regression", and then "Linear". This sequence of clicks will be denoted as Analyze/Regression/ in this text.
To understand the relationship between statistics and the scientific method and how it applies to psychology and the behavioral sciences.
To be able to read and understand the statistics presented in the professional literature.
To be able to calculate and communicate statistical information to others.
Throughout the book various icons or pictures will be placed in the left margin. They should be loosely interpreted as follows:
A Thought Question
An SPSS Data File
A Note to the Teacher
A Note to the Student
An Important Definitional Formula - MEMORIZE
A Computational Procedure.
An Example of a Procedure
David Stockburger has been teaching undergraduate and graduate statistics for twenty-six years as a professor of Psychology at Missouri State University. He earned his Ph.D. degree at the Ohio State University in 1975 with a major area of Mathematical Psychology and a minor area of Statistics. He has been involved during that time in the application of technology to education, specifically statistics education, and has presented papers and written numerous articles on the topic. One of his proudest accomplishments is the faculty sponsorship of a student-run Bulletin Board System for six years before the web became a common appliance. When off-campus, he resides with his wife in Springfield, Missouri and enjoys golf, tennis, camping, traveling, and developing computer software in his leisure time.
I wrote this book for a number of reasons, the most important one being my students. As I taught over a period of years, my approach to teaching introductory statistics began to deviate more and more from traditional textbooks. All too often students would come up to me and say that they seemed to understand the material in class, thought they took good notes, but when they got home the notes didn't seem to make much sense. Because the textbook I was using didn't seem to help much, I wrote this book. I took my lectures, added some documentation, and stirred everything with a word processor with this book as the result.
This book is dedicated to all the students I have had over the years. Some made me think about the material in ways that I had not previously done, questioning the very basis of what this course was all about. Others were a different challenge in terms of how I could explain what I knew and understood in a manner in which they could comprehend. All have had an impact in one way or another.
Three students had a more direct input into the book and deserve special mention. Eve Shellenberger, an ex-English teacher, earned many quarters discovering various errors in earlier editions of the text. Craig Shealy took his editorial pencil to a very early draft and improved the quality greatly. Wendy Hoyt has corrected many errors in the Web Edition. To all I am especially grateful.
I wish to thank my former dean, Dr. Jim Layton, and my department head, Dr. Fred Maxwell, both of whom found the necessary funds for hardware and software acquisition to enable this project. Recently I have received funds from the Southwest Missouri State University academic vice president, Dr. Bruno Schmidt, to assist me in the transfer of this text from paper to Web format.