Regression models are used to predict one variable from one or more other variables. Regression models provide the scientist with a powerful tool, allowing predictions about past, present, or future events to be made with information about past or present events. The scientist employs these models either because it is less expensive in terms of time and/or money to collect the information to make the predictions than to collect the information about the event itself, or, more likely, because the event to be predicted will occur in some future time. Before describing the details of the modeling process, however, some examples of the use of regression models will be presented.
Regression models are used for any number of purposes. They can help schools predict which students may need extra help-or extra challenges-in the classroom; assist medical professionals in anticipating problems their patients may develop; aid businesses in predicting which applicants would best help their companies; and help scientists predict earthquakes, to name just a few. Here are some examples of regression models at work.
A high school student discusses plans to attend college with a guidance counselor. The student has a 2.04 grade point average out of 4.00 maximum and mediocre to poor scores on the ACT. He asks about attending Harvard. The counselor tells him he would probably not do well at that institution, predicting he would have a grade point average of 0.64 at the end of four years at Harvard. The student inquires about the necessary grade point average to graduate and when told that it is 2.25, the student decides that maybe another institution might be more appropriate in case he becomes involved in some "heavy duty partying."
When asked about the large state university, the counselor predicts that he might succeed, but chances for success are not great, with a predicted grade point average of 1.23. A regional institution is then proposed, with a predicted grade point average of 1.54. Deciding that is still not high enough to graduate, the student decides to attend a local community college, graduates with an associate's degree and makes a fortune selling real estate.
If the counselor was using a regression model to make the predictions, he or she would know that although the regression model made very specific predictions, this particular student would probably not make a grade point of 0.64 at Harvard, 1.23 at the state university, and 1.54 at the regional university. These values are just "best guesses." It may be that this particular student was completely bored in high school, didn't take the standardized tests seriously, would become challenged in college and would succeed at Harvard. The selection committee at Harvard, however, when faced with a choice between a student with a predicted grade point of 3.24 and one with 0.64 would most likely make the rational decision of the most promising student.
A woman in the first trimester of pregnancy has a great deal of concern about the environmental factors surrounding her pregnancy and asks her doctor about what impact they might have on her unborn child. The doctor makes a "point estimate" based on a regression model that the child will have an IQ of 75. It is highly unlikely that her child will have an IQ of exactly 75, as there is always error in the regression procedure. Error may be incorporated into the information given the woman in the form of an "interval estimate." For example, it would make a great deal of difference to the woman in making her decision if the doctor were to say that the child had a ninety-five percent chance of having an IQ between 70 and 80 in contrast to a ninety-five percent chance of an IQ between 50 and 100. The concept of error in prediction is an important part of the discussion of regression models.
It is also worth pointing out that regression models do not make decisions for people. Regression models are a source of information about the world. In order to use them wisely, it is important to understand how they work.
Technology helped the United States and her allies to win the first and second world wars. One usually thinks of the atomic bomb, radar, bombsights, better designed aircraft, etc when this statement is made. Less well known were the contributions of psychologists and associated scientists to the development of tests and linear regression prediction models used for selection and placement of men and women in the armed forces.
During these wars, the United States had thousands of men and women enlisting or being drafted into the military. These individuals differed in their ability to perform physical and intellectual tasks. The problem was one of both selection, who is drafted and who is rejected, and placement, of those selected, who will cook and who will fight. The army that takes its best and brightest men and women and places them in the front lines digging trenches is less likely to win the war than the army who places these men and women in the position of leadership.
It costs a great deal of money and time to train a person to fly an airplane. Every time one crashes, the air force has lost a plane, the time and effort to train the pilot, and not to mention, the loss of the life of a person. For this reason it was, and still is, vital that the best possible selection and prediction tools be used for personnel decisions.
A new plant to manufacture widgets is being located in a nearby community. The plant personnel officer advertises the employment opportunity and the next morning has 10,000 people waiting to apply for the 1,000 available jobs. It is important to select the 1,000 people who will make the best employees because training takes time and money and firing is difficult and bad for community relations. In order to provide information to help make the correct decisions, the personnel officer employs a regression model.
In order to construct a regression model it is necessary to have information on both the variable we are predicting (the dependent variable) and the variable we are predicting from (the independent variable). This information is used to construct a prediction model that is used in the future. An understanding of the procedure used to create regression models is essential in order to answer the question "Why do we need to predict number of widgets made if we already know how many widgets were made?"
In order to construct a regression model, both the information which is going to be used to make the prediction and the information which is to be predicted must be obtained from a sample of objects or individuals. The relationship between the two pieces of information is then modeled with a linear transformation. Then in the future, only the first information is necessary, and the regression model is used to transform this information into the predicted. In other words, it is necessary to have information on both variables before the model can be constructed.
For example, the personnel officer of the widget manufacturing company might give all applicants a test and predict the number of widgets made per hour on the basis of the test score. In order to create a regression model, the personnel officer would first have to give the test to a sample of applicants and hire all of them. Later, when the number of widgets made per hour had stabilized, the personnel officer could create a prediction model to predict the widget production of future applicants. All future applicants would be given the test and hiring decisions would be based on test performance.
A notational scheme is now necessary to describe the procedure:
Xi is the variable used to predict, and is sometimes called the independent variable. In the case of the widget manufacturing example, it would be the test score.
Yi is the observed value of the predicted variable, and is sometimes called the dependent variable. In the example, it would be the number of widgets produced per hour by that individual.
Y'i is the predicted value of the dependent variable. In the example it would be the predicted number of widgets per hour by that individual.
The goal in the regression procedure is to create a model where the predicted and observed values of the variable to be predicted are as similar as possible. For example, in the widget manufacturing situation, it is desired that the predicted number of widgets made per hour be as similar to observed values as possible. The more similar these two values, the better the model. The next section presents a method of measuring the similarity of the predicted and observed values of the predicted variable.
In order to develop a measure of how well a model predicts the data, it is valuable to present an analogy of how to evaluate predictions. Suppose there were two interviewers, Mr. A and Ms. B, who separately interviewed each applicant for the widget manufacturing job for ten minutes. At the end of that time, the interviewer had to make a prediction about how many widgets that applicant would produce two months later. All of the applicants interviewed were hired, regardless of the predictions, and at the end of the two month's trial period, one interviewer, the best one, was to be retained and promoted, the other was to be fired. The purpose of the following is to develop a measure of goodness-of-fit, or, how well the interviewer predicted.
The notational scheme for the table is as follows:
Yi is the observed or actual number of widgets made per hour
Y'i is the predicted number of widgets
Suppose the data for the five applicants were as shown in this table:
| Interviewer | ||
|---|---|---|
| Observed | Mr. A | Ms. B |
| Yi | Y'i | Y'i |
| 23 | 38 | 21 |
| 18 | 34 | 15 |
| 35 | 16 | 32 |
| 10 | 10 | 8 |
| 27 | 14 | 23 |
Obviously neither interviewer was impressed with the fourth applicant, for good reason. A casual comparison of the two columns of predictions with the observed values leads one to believe that interviewer B made the better predictions. A procedure is desired which will provide a measure, or single number, of how well each interviewer performed.
The first step is to find how much each interviewer missed the predicted value for each applicant. This is done by finding the difference between the predicted and observed values for each applicant for each interviewer. These differences are called residuals. If the column of differences between the observed and predicted is summed,
 then it would appear that interviewer A is the better at prediction, because he had a smaller sum of deviations, 1, than interviewer B, with a sum of 14. This goes against common sense. In this case large positive deviations cancel out large negative deviations, leaving what appears as an almost perfect prediction for interviewer A, as you can see in the following table. But that is obviously not the case.
then it would appear that interviewer A is the better at prediction, because he had a smaller sum of deviations, 1, than interviewer B, with a sum of 14. This goes against common sense. In this case large positive deviations cancel out large negative deviations, leaving what appears as an almost perfect prediction for interviewer A, as you can see in the following table. But that is obviously not the case.
| Interviewer | ||||
|---|---|---|---|---|
| Observed | Mr. A | Ms . B | Mr. A | Ms. B |
| Yi | Y'i | Y'i | Yi - Y'i | Yi - Y'i |
| 23 | 38 | 21 | -15 | 2 |
| 18 | 34 | 15 | -16 | 3 |
| 35 | 16 | 32 | 19 | 3 |
| 10 | 10 | 8 | 0 | 2 |
| 27 | 14 | 23 | 13 | 4 |
| 1 | 14 | |||
In order to avoid the preceding problem, it is possible to ignore the signs of the differences and then sum, that is, take the sum of the absolute values. For mathematical reasons, however, statisticians eliminate the signs by squaring the differences. In the example, this procedure would yield the results shown in the following table:
| Interviewer | ||||||
|---|---|---|---|---|---|---|
| Observed | Mr. A | Ms . B | Mr. A | Ms. B | Mr. A | Ms. B |
| Yi | Y'i | Y'i | Yi - Y'i | Yi - Y'i | (Yi - Y'i)2 | (Yi - Y'i)2 |
| 23 | 38 | 21 | -15 | 2 | 225 | 4 |
| 18 | 34 | 15 | -16 | 3 | 256 | 9 |
| 35 | 16 | 32 | 19 | 3 | 361 | 9 |
| 10 | 10 | 8 | 0 | 2 | 0 | 4 |
| 27 | 14 | 23 | 13 | 4 | 169 | 16 |
| 1 | 14 | 1011 | 42 | |||
Summing the squared differences, or squared residuals, yields the desired measure of goodness-of-fit. In this case the smaller the number, the closer the predicted to the observed values. This is expressed in the following mathematical equation:
The prediction which minimizes this sum is said to meet the least-squares criterion. Interviewer B in the above example meets this criterion in a comparison between the two interviewers with values of 42 and 1011, respectively, and would be promoted. Interviewer A would receive a pink slip.
The situation using the regression model is analogous to that of the interviewers, except instead of using interviewers, predictions are made by performing a linear transformation of the predictor variable. The predicted value would be obtained by a linear transformation of the score. The prediction takes the form Y'=a+bX, where a and b are parameters in the regression model.
where a and b are parameters in the regression model.
In the above example, suppose that, rather than being interviewed each applicant took a form-board test (see figure below). A form-board is a board with holes cut out in various shapes: square, round, triangular, and so on. The goal is to put the right pegs in the right holes as fast as possible. The saying "square peg in a round hole" came from this test, which has been around for a long time.
The score for the test is the number of seconds it takes to complete putting all the pegs in the right holes. The data collected are shown in the following table:
| Form-Board Test | Widgets/hr |
|---|---|
| Xi | Yi |
| 13 | 23 |
| 20 | 18 |
| 10 | 35 |
| 33 | 10 |
| 15 | 27 |
Because the two parameters of the regression model, a and b, can take on any real value, there are an infinite number of possible models, analogous to having an infinite number of possible interviewers. The goal of regression is to select the parameters of the model so that the least-squares criterion is met, or, in other words, to minimize the sum of the squared deviations. The procedure discussed in the last chapter, that of transforming the scale of X to the scale of Y, such that both have the same mean and standard deviation will not work in this case, because of the prediction goal.
A number of possible models will now be examined where:
Xi is the number of seconds to complete the form board task
Yi is the number of widgets made per hour two months later
Y'i is the predicted number of widgets
For the first model, let a=10 and b=1, attempting to predict the first score perfectly. In this case the regression model becomes
The first score (X1=13) would be transformed into a predicted score of Y1'= 10 + (1*13) = 23. The second predicted score, where X2 = 20 would be Y2'= 10 + (1*20) = 30. The same procedure is then applied to the last three scores, resulting in predictions of 20, 43, and 25, respectively, as this table shows:
| Form-Board | Widgets/hr | Predicted | Residuals | Squared Residuals |
|---|---|---|---|---|
| Xi | Yi | Y'i=a+bXi | (Yi-Y'i) | (Yi-Y'i)2 |
| 13 | 23 | 23 | 0 | 0 |
| 20 | 18 | 30 | -12 | 144 |
| 10 | 35 | 20 | 15 | 225 |
| 33 | 10 | 43 | -33 | 1089 |
| 15 | 27 | 25 | 2 | 4 |
| (Yi-Y'i)2 | 1462 |
It can be seen that the model does a good job of prediction for the first and last applicant, but the middle applicants are poorly predicted. The sum of squared residuals in this case is 1462 and because it is desired that the model work for all applicants, some other values for the parameters must be tried.
The selection of the parameters for the second model is based on the observation that the longer it takes to put the form board together, the fewer the number of widgets made. When the tendency is for one variable to increase while the other decreases, the relationship between the variables is said to be inverse. In order to model an inverse relationship, a negative value of b must be used in the regression model. In this case the parameters of a=36 and b=-1 are used. This table shows the results.
| Form-Board | Widgets/hr | Predicted | Residuals | Squared Residuals |
|---|---|---|---|---|
| Xi | Yi | Y'i=a+bXi | (Yi-Y'i) | (Yi-Y'i)2 |
| 13 | 23 | 23 | 0 | 0 |
| 20 | 18 | 16 | 2 | 4 |
| 10 | 35 | 26 | 9 | 81 |
| 33 | 10 | 3 | 7 | 49 |
| 15 | 27 | 21 | 6 | 36 |
| (Yi-Y'i)2 | 170 |
This model, with a sum of squared residuals equal to 170, fits the data much better than did the first model. Fairly large deviations are noted for the third applicant, which might be reduced by increasing the value of the additive component of the transformation, a. Thus a model with a=41 and b=-1 are tried and the results are in the following table:
| Form-Board | Widgets/hr | Predicted | Residuals | Squared Residuals |
|---|---|---|---|---|
| Xi | Yi | Y'i=a+bXi | (Yi-Y'i) | (Yi-Y'i)2 |
| 13 | 23 | 28 | -5 | 25 |
| 20 | 18 | 21 | -3 | 19 |
| 10 | 35 | 31 | 4 | 16 |
| 33 | 10 | 8 | 2 | 4 |
| 15 | 27 | 26 | 1 | 1 |
| (Yi-Y'i)2 | 55 |
This makes the predicted values closer to the observed values on the whole, as measured by the sum of squared residuals, in this case equal to 55. Perhaps a decrease in the value of b would make the predictions better. Hence a model where a=32 and b=-.5 are tried. . You can see the results in this table:
| Form-Board | Widgets/hr | Predicted | Residuals | Squared Residuals |
|---|---|---|---|---|
| Xi | Yi | Y'i=a+bXi | (Yi-Y'i) | (Yi-Y'i)2 |
| 13 | 23 | 25.5 | -2.5 | 6.25 |
| 20 | 18 | 22 | -4 | 16 |
| 10 | 35 | 27 | 8 | 64 |
| 33 | 10 | 17.5 | -7.5 | 56.25 |
| 15 | 27 | 24.5 | 3.5 | 12.25 |
| (Yi-Y'i)2 | 142.5 |
Since the attempt increased the sum of the squared residuals to 142.5, it obviously was not a good idea.
The point is soon reached when the question, "When do we know when to stop?" must be asked. Using this procedure, the answer must necessarily be "never", because it is always possible to change the values of the two parameters slightly and obtain a better estimate, one that makes the sum of squared deviations smaller. The following table summarizes what is known about the problem thus far.
| a | b | (Yi-Y'i)2 |
|---|---|---|
| 10 | 1 | 1462 |
| 36 | -1 | 170 |
| 41 | -1 | 55 |
| 32 | -.5 | 142.5 |
With four attempts at selecting parameters for a model, it appears that when a=41 and b=-1, the best-fitting (smallest sum of squared deviations) is found to this point in time. If the same search procedure were going to be continued, perhaps the value of a could be adjusted when b=-2 and b=-1.5, and so forth. The following program provides scroll bars to allow the student to adjust the values of "a" and "b" and view the resulting table of squared residuals. Unless the sum of squared deviations is equal to zero, which is seldom possible in the real world, we will never know if it is the best possible model. Rather than throwing their hands up in despair, applied statisticians approached the mathematician with the problem and asked if a mathematical solution could be found. This is the topic of the next section. If the student is simply willing to "believe" it may be skimmed without any great loss of the ability to "do" a linear regression problem.
The problem is presented to the mathematician as follows: "The values of a and b in the linear model Y'i = a + bXi are to be found which minimize the algebraic expression

The mathematician begins as this figure shows:
Now comes the hard part that requires knowledge of calculus. At this point even the mathematically sophisticated student will be asked to "believe." What the mathematician does is take the first-order partial derivative of the last form of the preceding expression with respect to b, set it equal to zero, and solve for the value of b. This is the method that mathematicians use to solve for minimum and maximum values. Completing this task, the solution for the slope of the regression model becomes:
Using a similar procedure to find the value of a yields the least-square solution for the intercept:
The optimal values for a and b can be found by doing the appropriate summations, plugging them into the equations, and solving for the results. The appropriate summations are presented where:
| Xi | Yi | Xi2 | XiYi | |
|---|---|---|---|---|
| 13 | 23 | 169 | 299 | |
| 20 | 18 | 400 | 360 | |
| 10 | 35 | 100 | 350 | |
| 33 | 10 | 1089 | 330 | |
| 15 | 27 | 225 | 405 | |
| SUM | 91 | 113 | 1983 | 1744 |
The sums in the table above may be written in the shorthand mathematical summation notation as follows:
The result of these calculations (see the following figure) is a regression model of the form:
Solving for the a parameter, after solving for the b parameter, is somewhat easier, as this figure shows.
This procedure results in an optimal model. That is, no other values of a and b will yield a smaller sum of squared deviations. The mathematician is willing to bet the family farm on this result. A demonstration of this fact will be done for this problem shortly.
In any case, both the number of pairs of numbers (five) and the integer nature of the numbers made this problem "easy." This "easy" problem resulted in considerable computational effort. Imagine what a "difficult" problem with hundreds of pairs of decimal numbers would be like. That is why a bivariate, or two variable, statistics mode is available on many calculators.
Most statistical calculators require a number of steps to solve regression problems (the specific keystrokes required for the steps vary for the different makes and models of calculators; please consult the calculator manual for details):
The correlation coefficient (r)
The parameter estimates of the regression model
The results of these calculations for the example problem are shown in the following figure:
The discussion of the correlation coefficient is left for the next chapter. All that is important at the present time is the ability to calculate the value in the process of performing a regression analysis. The value of the correlation coefficient will be used in a later formula in this chapter.
Using either the algebraic expressions developed by the mathematician or the calculator, the optimal regression model results in the following:
Applying procedures identical to those used on earlier non-optimal regression models, the residuals (deviations of observed and predicted values) are found, squared, and summed to find the sum of squared deviations.
| Form-Board | Widgets/hr | Predicted | Residuals | Squared Residuals |
|---|---|---|---|---|
| Xi | Yi | Y'i=a+bXi | (Yi-Y'i) | (Yi-Y'i)2 |
| 13 | 23 | 27.58 | -4.57 | 20.88 |
| 20 | 18 | 20.88 | -2.78 | 8.28 |
| 10 | 35 | 30.44 | 4.55 | 20.76 |
| 33 | 10 | 8.44 | 1.56 | 2.42 |
| 15 | 27 | 25.66 | 1.34 | 1.80 |
| (Yi-Y'i)2 | 54.14 |
Note that the sum of squared deviations ((Yi-Y'i)2=54.14) is smaller than the previous low of 55.0, but not by much. The mathematician is willing to guarantee that this is the smallest sum of squared deviations that can be obtained by using any possible values for a and b.
The bottom line is that the equation
will be used to predict the number of widgets per hour that a potential employee will make, given the score that he or she has made on the form-board test. The prediction will not be perfect, but it will be the best available, given the data and the form of the model.
The preceding has been an algebraic presentation of the logic underlying the regression procedure. There is a one-to-one correspondence between algebra and geometry, and some students have an easier time understanding a visual presentation of an algebraic procedure, so let's look at one now. The data will be represented as points on a scatter plot, while the regression equation will be represented by a straight line, called the regression line.
A scatter plot or scatter gram is a visual representation of the relationship between the X and Y variables. First, the X and Y axes are drawn with equally spaced markings to include all values of that variable that occur in the sample. In the example problem, X, the seconds to put the form-board together, would have to range between 10 and 33, the lowest and highest values that occur in the sample. A similar value for the Y variable, the number of widgets made per hour, is from 10 to 35. If the axes do not start at zero, as in the present case where they both start at 10, a small space is left before the line markings to indicate this fact.
The paired or bivariate data (two variable, X,Y) will be represented as vectors or points on this graph. The point is plotted by finding the intersection of the X and Y scores for that pair of values. For example, the first point would be located at the intersection of and X=13 and Y=23. The first point and the remaining four points are presented on the following graph.
The regression line is drawn by plotting the X and Y' values. The next figure presents the five X and Y' values that were found on the regression table of observed and predicted values. Note that the first point would be plotted as (13, 27.57) the second point as (20, 20.88), etc.
Note that all the points fall on a straight line. If every possible Y' were plotted for every possible X, then a straight line would be formed. The equation Y' = a + bX defines a straight line in a two dimensional space. The easiest way to draw the line is to plot the two extreme points, that is, the points corresponding to the smallest and largest X and connect these points with a straightedge. Any two points would actually work, but the two extreme points give a line with the least drawing error. The a value is sometimes called the intercept and defines where the line crosses the Y-axis. This does not happen very often in actual drawings, because the axes do not begin at zero, that is, there is a break in the line. The following illustrates how to draw the regression line.
Most often the scatter plot and regression line are combined, as this graph shows:
The standard error of estimate is a measure of error in prediction. It is symbolized as sY.X, read as s sub Y dot X. The notation is used to mean the standard deviation of Y given the value of X is known. The standard error of estimate is defined by the formula
As such it may be thought of as the average deviation of the predicted from the observed values of Y, except the denominator is not N, but N-2, the degrees of freedom for the regression procedure. One degree of freedom is lost for each of the parameters estimated, a and b. Note that the numerator is the same as in the least-squares criterion.
The standard error of estimate is a standard deviation type of measure. Note the similarity of the definitional formula of the standard deviation of Y to the definitional formula for the standard error of measurement.
Two differences appear. First, the standard error of estimate divides the sum of squared deviations by N-2, rather than N-1. Second, the standard error of estimate finds the sum of squared differences around a predicted value of Y, rather than the mean.
The similarity of the two measures may be resolved if the standard deviation of Y is conceptualized as the error around a predicted Y of Y'i = a. When the least-squares criterion is applied to this model, the optimal value of a is the mean of Y. In this case only one degree of freedom is lost because only one parameter is estimated for the regression model.
The standard error of estimate may be calculated from the definitional formula given above. The computation is difficult, however, because the entire table of differences and squared differences must be calculated. Because the numerator has already been found, the calculation for the example data is relatively easy, as the following formula shows:
The calculation of the standard error of estimate is simplified by the following formula, called the computational formula for the standard error of estimate. The computation is easier because the statistical calculator computed the correlation coefficient when finding a regression line. The computational formula for the standard error of estimate will always give the same result, within rounding error, as the definitional formula. The computational formula may look more complicated, but it does not require the computation of the entire table of differences between observed and predicted Y scores. The computational formula is:
The computational formula for the standard error of estimate is most easily and accurately computed by temporality storing the values for sY2 and r2 in the calculator's memory and recalling them when needed. Using this formula to calculate the standard error of estimate with the example data produces the following results
Note that the result is the same as the result from the application of the definitional formula, within rounding error.
The standard error of estimate is a measure of error in prediction. The larger its value, the less well the regression model fits the data, and the worse the prediction.
A conditional distribution is a distribution of a variable given a particular value of another variable. For example, a conditional distribution of number of widgets made exists for each possible value of number of seconds to put the form board together. Conceptually, suppose that an infinite number of applicants had made the same score of 18 on the form board test. If everyone was hired, not everyone would make the same number of widgets three months later. The distribution of scores which results would be called the conditional distribution of Y (widgets) given X (form board). The relationship between X and Y in this case is often symbolized by Y|X. The conditional distribution of Y given that X was 18 would be symbolized as Y|X=18.
It is possible to model the conditional distribution with the normal curve. In order to create a normal curve model, it is necessary to estimate the values of the parameters of the model, mY|X and dY|X. The best estimate of mY|X is the predicted value of Y, Y', given X equals a particular value. This is found by entering the appropriate value of X in the regression equation, Y'=a+bX. In the example, the estimate of mY|X for the conditional distribution of number of widgets made given X=18, would be Y'=40.01-.957*18=22.78. This value is also called a point estimate, because it is the best guess of Y when X is a given value.
The standard error of estimate is often used as an estimate of dY |X for all the conditional distributions. This assumes that all conditional distributions have the same value for this parameter. One interpretation of the standard error of estimate, then, is an estimate of the value of dY |X for all possible conditional distributions or values of X. The conditional distribution which results when X=18 is presented here.
It is somewhat difficult to visualize all possible conditional distributions in only two dimensions, although the following illustration attempts the relatively impossible. If a hill can be visualized with the middle being the regression line, the vision would be essentially correct.
The conditional distribution is a model of the distribution of points around the regression line for a given value of X. The conditional distribution is important in this text mainly for the role it plays in computing an interval estimate.
The error in prediction may be incorporated into the information given to the client by using interval estimates rather than point estimates. A point estimate is the predicted value of Y, Y'. While it gives the best possible prediction, as defined by the least-squares criterion, the prediction is not perfect. The interval estimate presents two values; low and high, between which some percentage of the observed scores are likely to fall. For example, if a person applying for a position manufacturing widgets made a score of X=18 on the form board test, a point estimate of 22.78 would result from the application of the regression model and a ninety-five percent confidence interval estimate might be from 14.25 to 31.11. Using a ninety-five percent confidence interval, it can be said that 95 times out of 100 the number of widgets made per hour by an applicant making a score of 18 on the form board test would be between 14.25 and 31.11.
The concept of the conditional distribution is critical to understanding the assumptions made when calculating an interval estimate. If the conditional distribution for a value of X is known, then finding an interval estimate is reduced to a problem that has already been solved in an earlier chapter. That is, what two scores on a normal distribution with parameters and cut off some middle percent of the distribution? While any percentage could be found, the standard value is a 95% confidence interval.
For example, the parameter estimates of the conditional distribution of X=18 are mY|X=22.78 and dY|X=4.25. The two scores which cut off the middle 95% of that distribution are 14.25 and 31.11. Use of the Probability Calculator to find the middle area. Here are the steps, as shown in the following figure:
Other sizes of confidence intervals could be computed by changing the value of the probability in the Probability Calculator.
Interpretation of the confidence interval for a given score of X necessitates several assumptions. First, the conditional distribution for that X is a normal distribution. Second, mY|X is correctly estimated by Y', that is, the relationship between X and Y can be adequately modeled by a straight line. Third, dY|X is correctly estimated by sY.X, which means assuming that all conditional distributions have the same estimate for dY|X.
Probability Calculator
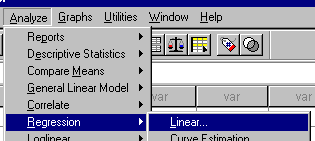
To use the Regression command in SPSS, select Analyze/Regression/Linear, as the following figure shows.
On the screen that follows, click the Save button. In the pop-up Linear Regression:Save dialog box check Unstandardized in both the Predicted Values and the Residuals, as shown in the following figure. Clicking Continue and then OK will command the program to do a simple linear regression and create two new variables in the data editor: one with the predicted values of Y and the other with the residuals.
The first table of the output (see the following figure) from the preceding includes and standard error of estimate.
The regression coefficients, or values for a (intercept) and b (slope) are also found in the third table in the SPSS output. The values under B in the unstandardized coefficients are the intercept (Constant) and slope (FORMBRD). The values under the "Beta" column correspond to the regression weights when both x and y have been converted to z-scores. In this case, z of y is predicted from z of x.
The optional Save command generates two new variables in the data file: pre_1 (predicted Y) and res_1 (residuals). The data file will look like the following figure:
Regression models are powerful tools for predicting a score based on some other score. They involve a linear transformation of the predictor variable into the predicted variable. The parameters of the linear transformation are selected such that the least-squares criterion is met, resulting in an "optimal" model. The model can then be used in the future to predict either exact scores, called point estimates, or intervals of scores, called interval estimates.
Graphically the relationship between two variables can be represented in a scatter plot. A point on the scatter plot represents each pair of scores. The regression line is represented as a line on the graph. The closer the points fall to the line, the better the fit of the model to the data.